1、简介
Flink的特点是高吞吐低延迟。但是Flink中的某环节的数据处理逻辑需要和外部系统交互,调用耗时不可控会显著降低集群性能。这时候就可能需要使用异步算子让耗时操作不需要等待结果返回就可以继续下面的耗时操作。
2、本章可以了解到啥
- 异步算子源码分析
- 异步算子为啥能够保证有序性
- flinksql中怎么自定义使用异步lookup join
3、异步算子的测试代码
import java.io.Serializable;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 网上copy的模拟一个耗时的异步操作
*/
public class AsyncIODemo implements Serializable {
private final ExecutorService executorService = Executors.newFixedThreadPool(4);
public CompletableFuture<String> pullData(final String source) {
CompletableFuture<String> completableFuture = new CompletableFuture<>();
executorService.submit(() -> {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
/**
* 前面睡眠几秒后,调用一下完成方法,拼接一个结果字符串
*/
completableFuture.complete("Output value: " + source);
});
return completableFuture;
}
}import org.apache.flink.streaming.api.datastream.AsyncDataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.async.AsyncFunction;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import java.util.Arrays;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.TimeUnit;
/**
* 网上copy的代码
*/
public class AsyncTest {
public static void main(String[] args) throws Exception {
/**
* 获取Flink执行环境并设置并行度为1,方便后面观测
*/
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
/**
* 构造一个DataStreamSource的序列
*/
DataStreamSource stream = env.fromElements("11", "22", "33", "44");
/**
* 使用AsyncDataStream构造一个异步顺序流,这里异步顺序流从名字就可以看出来虽然是异步的,但是却可以保持顺序,
* 这个后面源码分析可以知道原因
*/
SingleOutputStreamOperator asyncStream = AsyncDataStream.orderedWait(stream, new AsyncFunction<String, String>() {
@Override
public void asyncInvoke(String input, ResultFuture<String> resultFuture) throws Exception {
/**
* 这里调用模拟的获取异步请求结果,并返回一个CompletableFuture
*/
CompletableFuture<String> future = new AsyncIODemo().pullData(input);
/**
* 注册一个future处理完成的回调,当future处理完成拿到结果后,调用resultFuture的
* complete方法真正吐出数据
*/
future.whenCompleteAsync((d,t) ->{
resultFuture.complete(Arrays.asList(d));
});
}
// 设置最长异步调用超时时间为10秒
}, 10, TimeUnit.SECONDS);
asyncStream.print();
env.execute();
}
}4、异步算子源码分析
4.1、AsyncDataStream
package org.apache.flink.streaming.api.datastream;
import org.apache.flink.annotation.PublicEvolving;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.Utils;
import org.apache.flink.api.java.typeutils.TypeExtractor;
import org.apache.flink.streaming.api.functions.async.AsyncFunction;
import org.apache.flink.streaming.api.operators.async.AsyncWaitOperator;
import org.apache.flink.streaming.api.operators.async.AsyncWaitOperatorFactory;
import java.util.concurrent.TimeUnit;
/**
* 用于将AsyncFunction应用到数据流的一个helper类
*
* <pre>{@code
* DataStream<String> input = ...
* AsyncFunction<String, Tuple<String, String>> asyncFunc = ...
*
* AsyncDataStream.orderedWait(input, asyncFunc, timeout, TimeUnit.MILLISECONDS, 100);
* }</pre>
*/
@PublicEvolving
public class AsyncDataStream {
/** 异步操作的输出模式,有序或者无序. */
public enum OutputMode {
ORDERED,
UNORDERED
}
private static final int DEFAULT_QUEUE_CAPACITY = 100;
/**
* flag_2,添加一个AsyncWaitOperator.
*
* @param in The {@link DataStream} where the {@link AsyncWaitOperator} will be added.
* @param func {@link AsyncFunction} wrapped inside {@link AsyncWaitOperator}.
* @param timeout for the asynchronous operation to complete
* @param bufSize The max number of inputs the {@link AsyncWaitOperator} can hold inside.
* @param mode Processing mode for {@link AsyncWaitOperator}.
* @param <IN> Input type.
* @param <OUT> Output type.
* @return A new {@link SingleOutputStreamOperator}
*/
private static <IN, OUT> SingleOutputStreamOperator<OUT> addOperator(
DataStream<IN> in,
AsyncFunction<IN, OUT> func,
long timeout,
int bufSize,
OutputMode mode) {
TypeInformation<OUT> outTypeInfo =
TypeExtractor.getUnaryOperatorReturnType(
func,
AsyncFunction.class,
0,
1,
new int[] {1, 0},
in.getType(),
Utils.getCallLocationName(),
true);
/**
这里生成了一个AsyncWaitOperatorFactory
*/
AsyncWaitOperatorFactory<IN, OUT> operatorFactory =
new AsyncWaitOperatorFactory<>(
in.getExecutionEnvironment().clean(func), timeout, bufSize, mode);
return in.transform("async wait operator", outTypeInfo, operatorFactory);
}
/**
* 添加一个AsyncWaitOperator。输出流无顺序。
*
* @param in Input {@link DataStream}
* @param func {@link AsyncFunction}
* @param timeout for the asynchronous operation to complete
* @param timeUnit of the given timeout
* @param capacity The max number of async i/o operation that can be triggered
* @param <IN> Type of input record
* @param <OUT> Type of output record
* @return A new {@link SingleOutputStreamOperator}.
*/
public static <IN, OUT> SingleOutputStreamOperator<OUT> unorderedWait(
DataStream<IN> in,
AsyncFunction<IN, OUT> func,
long timeout,
TimeUnit timeUnit,
int capacity) {
return addOperator(in, func, timeUnit.toMillis(timeout), capacity, OutputMode.UNORDERED);
}
/**
* 添加一个AsyncWaitOperator。输出流无顺序。
* @param in Input {@link DataStream}
* @param func {@link AsyncFunction}
* @param timeout for the asynchronous operation to complete
* @param timeUnit of the given timeout
* @param <IN> Type of input record
* @param <OUT> Type of output record
* @return A new {@link SingleOutputStreamOperator}.
*/
public static <IN, OUT> SingleOutputStreamOperator<OUT> unorderedWait(
DataStream<IN> in, AsyncFunction<IN, OUT> func, long timeout, TimeUnit timeUnit) {
return addOperator(
in, func, timeUnit.toMillis(timeout), DEFAULT_QUEUE_CAPACITY, OutputMode.UNORDERED);
}
/**
* flag_1,添加一个AsyncWaitOperator。处理输入记录的顺序保证与输入记录的顺序相同
*
* @param in Input {@link DataStream}
* @param func {@link AsyncFunction}
* @param timeout for the asynchronous operation to complete
* @param timeUnit of the given timeout
* @param capacity The max number of async i/o operation that can be triggered
* @param <IN> Type of input record
* @param <OUT> Type of output record
* @return A new {@link SingleOutputStreamOperator}.
*/
public static <IN, OUT> SingleOutputStreamOperator<OUT> orderedWait(
DataStream<IN> in,
AsyncFunction<IN, OUT> func,
long timeout,
TimeUnit timeUnit,
int capacity) {
return addOperator(in, func, timeUnit.toMillis(timeout), capacity, OutputMode.ORDERED);
}
/**
* 添加一个AsyncWaitOperator。处理输入记录的顺序保证与输入记录的顺序相同
* @param in Input {@link DataStream}
* @param func {@link AsyncFunction}
* @param timeout for the asynchronous operation to complete
* @param timeUnit of the given timeout
* @param <IN> Type of input record
* @param <OUT> Type of output record
* @return A new {@link SingleOutputStreamOperator}.
*/
public static <IN, OUT> SingleOutputStreamOperator<OUT> orderedWait(
DataStream<IN> in, AsyncFunction<IN, OUT> func, long timeout, TimeUnit timeUnit) {
return addOperator(
in, func, timeUnit.toMillis(timeout), DEFAULT_QUEUE_CAPACITY, OutputMode.ORDERED);
}
}如上从测试代码开始调用链为:AsyncDataStream.orderedWait -> addOperator,然后addOperator中new了一个AsyncWaitOperatorFactory。然后到这里其实可以告一段落了,因为没有必要往下看了,这个时候就需要猜了,一般我们类名叫XXFactory基本都是工厂模式,然后工厂生产的就是XX了,这里就是生成AsyncWaitOperator对象的工厂了,然后我们就可以直接在AsyncWaitOperator类的构造方法第一行打个断点,看看啥时候会进去了。为啥要这样做,因为我们看到的Flink源码其实并不是一个线性的执行过程,架构图如下
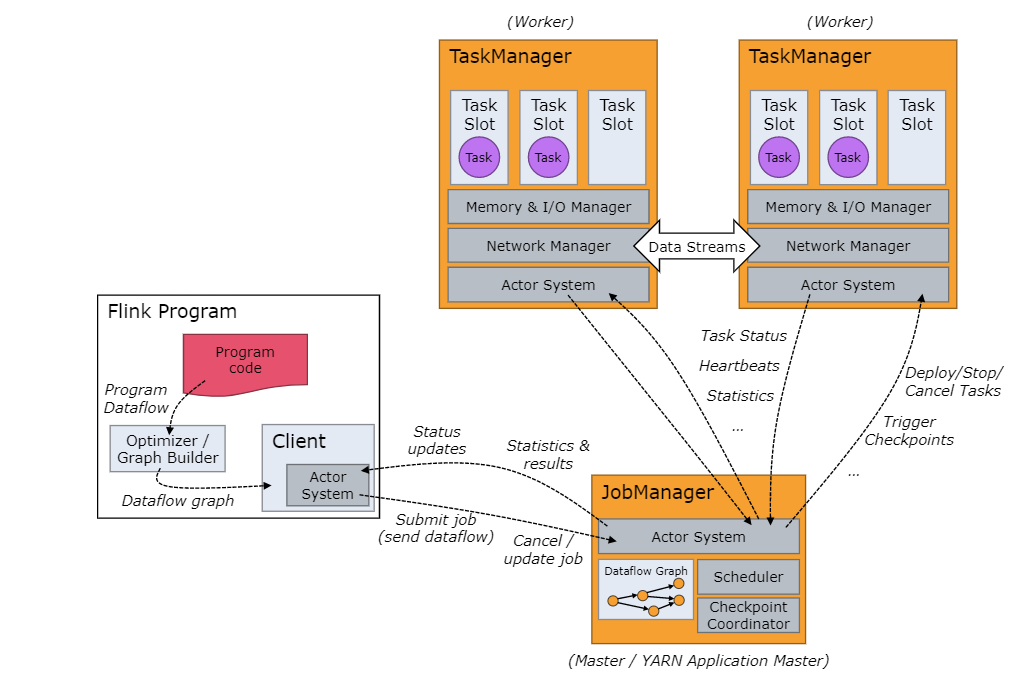
他的代码实际上并不是都在一个节点执行,虽然我们在本地调试,但是也是在模拟的一个本地集群中执行,怎么模拟出不同的节点呢,很明显要通过线程,也就是说不同的节点用不同的线程来代表并执行。所以我们无脑断点是没法看到全貌的。看代码的一个技巧,根据各方面的经验猜测,比如这里就是根据类名的特点进行猜测。
4.2、AsyncWaitOperator
我们在AsyncWaitOperator类的所有公共方法和构造方法里打个断点,debug运行程序进入调试
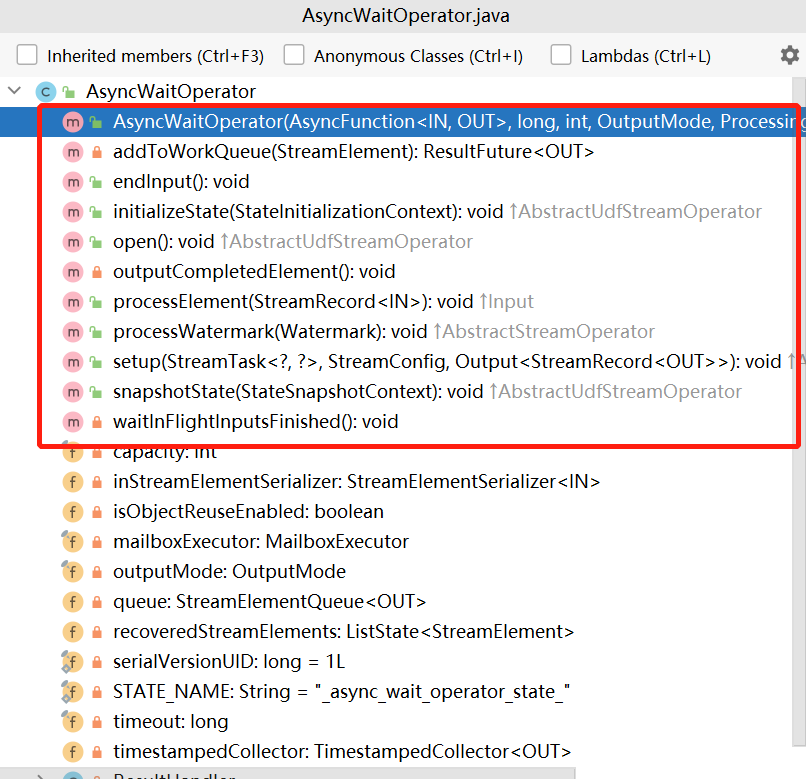

很明显这个构造方法,在一个独立的sink线程中运行,如果还按照上面的方式断点,估计找一辈子都找不到了
public AsyncWaitOperator(
@Nonnull AsyncFunction<IN, OUT> asyncFunction,
long timeout,
int capacity,
@Nonnull AsyncDataStream.OutputMode outputMode,
@Nonnull ProcessingTimeService processingTimeService,
@Nonnull MailboxExecutor mailboxExecutor) {
super(asyncFunction);
setChainingStrategy(ChainingStrategy.ALWAYS);
Preconditions.checkArgument(
capacity > 0, "The number of concurrent async operation should be greater than 0.");
this.capacity = capacity;
this.outputMode = Preconditions.checkNotNull(outputMode, "outputMode");
this.timeout = timeout;
this.processingTimeService = Preconditions.checkNotNull(processingTimeService);
this.mailboxExecutor = mailboxExecutor;
}我们看一下构造方法的内容,发现都是一些初始化操作,看着没啥营养,看代码的另外一个技巧:抓大放小,路边的野花不要理睬,忽略一些不重要的初始化和参数校验等代码,重点关注大的流程的东西。
我们继续直接放开往下运行,直到下一个断点
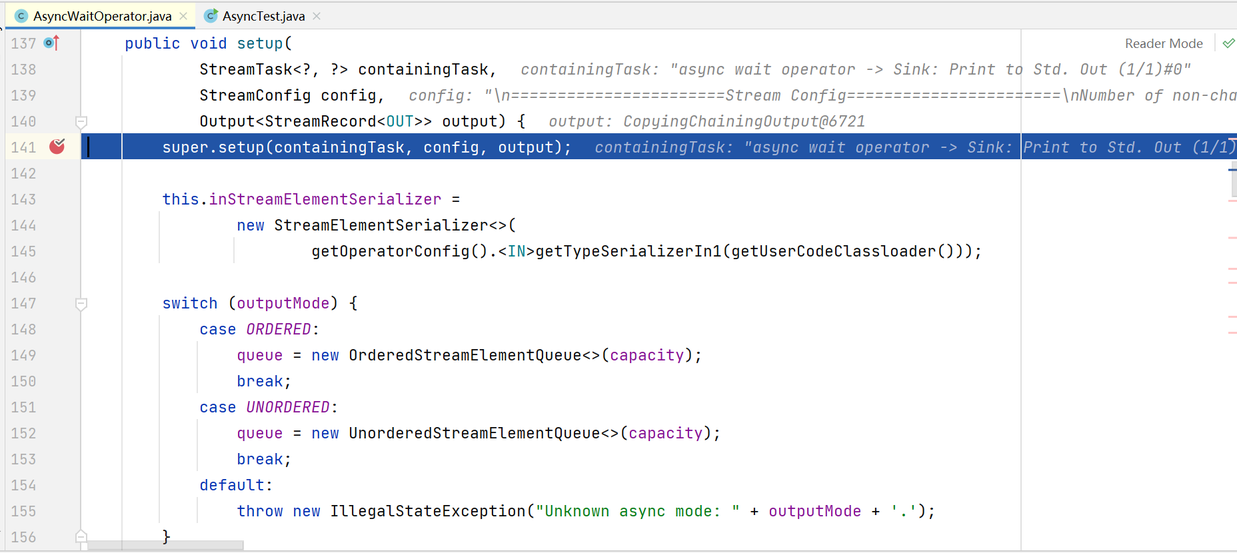
@Override
public void setup(
StreamTask<?, ?> containingTask,
StreamConfig config,
Output<StreamRecord<OUT>> output) {
super.setup(containingTask, config, output);
this.inStreamElementSerializer =
new StreamElementSerializer<>(
getOperatorConfig().<IN>getTypeSerializerIn1(getUserCodeClassloader()));
switch (outputMode) {
case ORDERED:
queue = new OrderedStreamElementQueue<>(capacity);
break;
case UNORDERED:
queue = new UnorderedStreamElementQueue<>(capacity);
break;
default:
throw new IllegalStateException("Unknown async mode: " + outputMode + '.');
}
this.timestampedCollector = new TimestampedCollector<>(super.output);
}一眼望去就发现下面switch case那里比较有用,根据名字可以知道,这里根据outputMode判断分别实例化有序的队列和无需的队列,联想到AsyncDataStream类里的几个orderedWait和unorderedWait方法,很快就能想到是否有序这个队列就是关键了。好了没什么可以留恋了,继续执行到下一个断点吧!
初始化状态,没啥可留恋的,先跳过继续到下一个断点

@Override
public void open() throws Exception {
super.open();
this.isObjectReuseEnabled = getExecutionConfig().isObjectReuseEnabled();
if (recoveredStreamElements != null) {
for (StreamElement element : recoveredStreamElements.get()) {
if (element.isRecord()) {
processElement(element.<IN>asRecord());
} else if (element.isWatermark()) {
processWatermark(element.asWatermark());
} else if (element.isLatencyMarker()) {
processLatencyMarker(element.asLatencyMarker());
} else {
throw new IllegalStateException(
"Unknown record type "
+ element.getClass()
+ " encountered while opening the operator.");
}
}
recoveredStreamElements = null;
}
}如上从7行开始貌似是开始处理数据了,但是根据recoveredStreamElements这个名称一看,很显然recovered是恢复的意思,这里判断是否为空,不为空再做,很明显是做修复数据相关的逻辑,我们处理数据的正主都没找到这里很明显没啥意义,属于路边的野花,直接忽略到下一个断点去。

@Override
public void processElement(StreamRecord<IN> record) throws Exception {
StreamRecord<IN> element;
// copy the element avoid the element is reused
if (isObjectReuseEnabled) {
//noinspection unchecked
element = (StreamRecord<IN>) inStreamElementSerializer.copy(record);
} else {
element = record;
}
// add element first to the queue
final ResultFuture<OUT> entry = addToWorkQueue(element);
final ResultHandler resultHandler = new ResultHandler(element, entry);
// register a timeout for the entry if timeout is configured
if (timeout > 0L) {
resultHandler.registerTimeout(getProcessingTimeService(), timeout);
}
userFunction.asyncInvoke(element.getValue(), resultHandler);
}很明显根据方法名称可以知道这里就是在处理真正的数据了,反复断点几次,可以发现,每一条数据都会进来这个方法一次

这个方法的参数就是source流里的一个元素,下面我们再看一下addToWorkQueue方法吧
/**
将给定的流元素添加到操作符的流元素队列中。该操作会阻塞,直到元素被添加。
*/
private ResultFuture<OUT> addToWorkQueue(StreamElement streamElement)
throws InterruptedException {
Optional<ResultFuture<OUT>> queueEntry;
while (!(queueEntry = queue.tryPut(streamElement)).isPresent()) {
mailboxExecutor.yield();
}
return queueEntry.get();
}这个方法就是将前面source里的元素放入前面new出来的队列,本例这里是一个有序的队列OrderedStreamElementQueue,并返回了一个ResultFuture对象,我们需要看一下这个对象是个啥
4.3、ResultFuture
@PublicEvolving
public interface ResultFuture<OUT> {
/**
* 将所有结果放在Collection中,然后输出。
*/
void complete(Collection<OUT> result);
/**
* 将异常输出
*/
void completeExceptionally(Throwable error);
}我们再来看下tryPut是如何包装出了一个ResultFuture对象的
4.4、OrderedStreamElementQueue
@Internal
public final class OrderedStreamElementQueue<OUT> implements StreamElementQueue<OUT> {
private static final Logger LOG = LoggerFactory.getLogger(OrderedStreamElementQueue.class);
/** Capacity of this queue. */
private final int capacity;
/** Queue for the inserted StreamElementQueueEntries. */
private final Queue<StreamElementQueueEntry<OUT>> queue;
public OrderedStreamElementQueue(int capacity) {
Preconditions.checkArgument(capacity > 0, "The capacity must be larger than 0.");
this.capacity = capacity;
this.queue = new ArrayDeque<>(capacity);
}
@Override
public boolean hasCompletedElements() {
return !queue.isEmpty() && queue.peek().isDone();
}
@Override
public void emitCompletedElement(TimestampedCollector<OUT> output) {
if (hasCompletedElements()) {
final StreamElementQueueEntry<OUT> head = queue.poll();
head.emitResult(output);
}
}
@Override
public List<StreamElement> values() {
List<StreamElement> list = new ArrayList<>(this.queue.size());
for (StreamElementQueueEntry e : queue) {
list.add(e.getInputElement());
}
return list;
}
@Override
public boolean isEmpty() {
return queue.isEmpty();
}
@Override
public int size() {
return queue.size();
}
@Override
public Optional<ResultFuture<OUT>> tryPut(StreamElement streamElement) {
if (queue.size() < capacity) {
StreamElementQueueEntry<OUT> queueEntry = createEntry(streamElement);
queue.add(queueEntry);
LOG.debug(
"Put element into ordered stream element queue. New filling degree "
+ "({}/{}).",
queue.size(),
capacity);
return Optional.of(queueEntry);
} else {
LOG.debug(
"Failed to put element into ordered stream element queue because it "
+ "was full ({}/{}).",
queue.size(),
capacity);
return Optional.empty();
}
}
private StreamElementQueueEntry<OUT> createEntry(StreamElement streamElement) {
if (streamElement.isRecord()) {
return new StreamRecordQueueEntry<>((StreamRecord<?>) streamElement);
}
if (streamElement.isWatermark()) {
return new WatermarkQueueEntry<>((Watermark) streamElement);
}
throw new UnsupportedOperationException("Cannot enqueue " + streamElement);
}
}我们重点关注一下52行以下的部分,可以看到new了一个StreamElementQueueEntry对象放入了queue队列中,那就需要看一下StreamRecordQueueEntry类了
4.5、StreamRecordQueueEntry
@Internal
class StreamRecordQueueEntry<OUT> implements StreamElementQueueEntry<OUT> {
@Nonnull private final StreamRecord<?> inputRecord;
private Collection<OUT> completedElements;
StreamRecordQueueEntry(StreamRecord<?> inputRecord) {
this.inputRecord = Preconditions.checkNotNull(inputRecord);
}
@Override
public boolean isDone() {
return completedElements != null;
}
@Nonnull
@Override
public StreamRecord<?> getInputElement() {
return inputRecord;
}
@Override
public void emitResult(TimestampedCollector<OUT> output) {
output.setTimestamp(inputRecord);
for (OUT r : completedElements) {
output.collect(r);
}
}
@Override
public void complete(Collection<OUT> result) {
this.completedElements = Preconditions.checkNotNull(result);
}
}如上之后,现在已经可以有一个大概的认识了,就是随着程序的运行,一个个的数据被封装成了StreamRecordQueueEntry对象,并阻塞的放入了OrderedStreamElementQueue队列中了,这个队列中的StreamRecordQueueEntry对象有一些方法标志性的方法,如:isDone,根据名字就可以知道是否完成的意思;emitResult方法如果写过flink程序的人一看到output.collect(r)这种代码就知道是向下游发出数据的方法;complete方法字母意思就是一个完成动作方法,内容就是把传入的数据判空后赋给了成员变量completedElements。
我们继续回到processElement方法的主线上来,
// 首先将元素添加到队列中
final ResultFuture<OUT> entry = addToWorkQueue(element);
final ResultHandler resultHandler = new ResultHandler(element, entry);
// 如果配置了timeout,则为条目注册一个超时,这里的timeout也就是测试代码里的10s
if (timeout > 0L) {
resultHandler.registerTimeout(getProcessingTimeService(), timeout);
}
userFunction.asyncInvoke(element.getValue(), resultHandler);关注上面的最后一行,执行了asyncInvoke方法,也就回到了测试代码里覆写的asyncInvoke方法里了
/**
* 使用AsyncDataStream构造一个异步顺序流,这里异步顺序流从名字就可以看出来虽然是异步的,但是却可以保持顺序,
* 这个后面源码分析可以知道原因
*/
SingleOutputStreamOperator asyncStream = AsyncDataStream.orderedWait(stream, new AsyncFunction<String, String>() {
@Override
public void asyncInvoke(String input, ResultFuture<String> resultFuture) throws Exception {
/**
* 这里调用模拟的获取异步请求结果,并返回一个CompletableFuture
*/
CompletableFuture<String> future = new AsyncIODemo().pullData(input);
/**
* 注册一个future处理完成的回调,当future处理完成拿到结果后,调用resultFuture的
* complete方法真正吐出数据
*/
future.whenCompleteAsync((d,t) ->{
resultFuture.complete(Arrays.asList(d));
});
}
// 设置最长异步调用超时时间为10秒
}, 10, TimeUnit.SECONDS);这时候我们可以打个断点到如上测试代码的17行上,然后执行进入方法,可以看到实际上回到了org.apache.flink.streaming.api.operators.async.AsyncWaitOperator.ResultHandler这个内部类里的complete方法
private void outputCompletedElement() {
/**
判断这个OrderedStreamElementQueue队列有没有完成了的元素,参见上面代码
@Override
public boolean hasCompletedElements() {
return !queue.isEmpty() && queue.peek().isDone();
}
其实就是查看了一下队列头的元素StreamRecordQueueEntry,调用了一下isDone方法
@Override
public boolean isDone() {
return completedElements != null;
}
就是判断成员变量是不是空,因为上一步已经赋值了,所以这里isDone就返回true了
*/
if (queue.hasCompletedElements()) {
/**
调用了一下OrderedStreamElementQueue队列的emitCompletedElement方法,
@Override
public void emitCompletedElement(TimestampedCollector<OUT> output) {
if (hasCompletedElements()) {
final StreamElementQueueEntry<OUT> head = queue.poll();
head.emitResult(output);
}
}
移除队列的头元素StreamElementQueueEntry,并调用其emitResult方法
@Override
public void emitResult(TimestampedCollector<OUT> output) {
output.setTimestamp(inputRecord);
for (OUT r : completedElements) {
output.collect(r);
}
}
这里就是真正的循环调用collect把数据吐出到下游去了
*/
queue.emitCompletedElement(timestampedCollector);
// if there are more completed elements, emit them with subsequent mails
if (queue.hasCompletedElements()) {
try {
mailboxExecutor.execute(
this::outputCompletedElement,
"AsyncWaitOperator#outputCompletedElement");
} catch (RejectedExecutionException mailboxClosedException) {
// This exception can only happen if the operator is cancelled which means all
// pending records can be safely ignored since they will be processed one more
// time after recovery.
LOG.debug(
"Attempt to complete element is ignored since the mailbox rejected the execution.",
mailboxClosedException);
}
}
}
}
/** A handler for the results of a specific input record. */
private class ResultHandler implements ResultFuture<OUT> {
/** Optional timeout timer used to signal the timeout to the AsyncFunction. */
private ScheduledFuture<?> timeoutTimer;
/** Record for which this result handler exists. Used only to report errors. */
private final StreamRecord<IN> inputRecord;
/**
* The handle received from the queue to update the entry. Should only be used to inject the
* result; exceptions are handled here.
*/
private final ResultFuture<OUT> resultFuture;
/**
* A guard against ill-written AsyncFunction. Additional (parallel) invokations of {@link
* #complete(Collection)} or {@link #completeExceptionally(Throwable)} will be ignored. This
* guard also helps for cases where proper results and timeouts happen at the same time.
*/
private final AtomicBoolean completed = new AtomicBoolean(false);
ResultHandler(StreamRecord<IN> inputRecord, ResultFuture<OUT> resultFuture) {
this.inputRecord = inputRecord;
this.resultFuture = resultFuture;
}
@Override
public void complete(Collection<OUT> results) {
Preconditions.checkNotNull(
results, "Results must not be null, use empty collection to emit nothing");
// cas修改一下completed的状态,不成功就返回
if (!completed.compareAndSet(false, true)) {
return;
}
processInMailbox(results);
}
private void processInMailbox(Collection<OUT> results) {
// move further processing into the mailbox thread
mailboxExecutor.execute(
() -> processResults(results),
"Result in AsyncWaitOperator of input %s",
results);
}
private void processResults(Collection<OUT> results) {
/**
如果超时的Timer对象不为空,则将定时任务取消掉,因为这里已经是在完成方法里调用了,
数据都完成处理了,这个数据的超时任务就可以取消了
*/
if (timeoutTimer != null) {
// canceling in mailbox thread avoids
// https://issues.apache.org/jira/browse/FLINK-13635
timeoutTimer.cancel(true);
}
/**
这里调用了一下StreamRecordQueueEntry的complete方法将成员变量completedElements
赋值了,可以参见上面StreamRecordQueueEntry类
*/
resultFuture.complete(results);
// 这里看上面第1行代码
outputCompletedElement();
}
}我们可以从上面的ResultHandler类的complete方法开始看,具体可以参见上面注释,总结起来就是如下几步
- 取消当前ResultHandler对象的超时定时任务
- 调用StreamRecordQueueEntry的complete方法将成员变量completedElements赋值
- 判断OrderedStreamElementQueue队列的队头元素StreamRecordQueueEntry的completedElements成员变量是不是不为空
- 第3步不为空,则调用OrderedStreamElementQueue队列的emitCompletedElement方法移除队列的头元素StreamElementQueueEntry并调用emitResult方法真正向下游吐出数据
从上面可以看出每次随着completableFuture的complete方法的调用,都会判断队头的元素是否处理完,处理完就移除队头元素并向吐出数据。所以异步算子每次来数据经过processElement方法,就已经将数据元素封装成StreamElementQueueEntry对象并放到了队列中,虽然异步算子执行过程是异步,每个元素的完成时间没有顺序,但是由于每个元素完成后,都是判断的队头元素有没有完成,完成后也是移除队头并向下游吐数据。所以整体过程还是按照processElement处理顺序也就是上游给过来的数据顺序严格有序的。
5、flinksql自定义AsyncLookupFunction
通常flinksql使用外部的数据源都需要引入一个flinksql-connector-xx这种jar包,比如我们想以kafka为流表join一个redis的维表,那么这时候查询redis的维表,通常使用的就是lookup join。但是网上提供的例子基本都是同步的lookup join,在有些场景下为了提高吞吐就需要使用异步的lookup join。详细实现可以直接看代码:https://gitee.com/rongdi/flinksql-connector-redis
标签:
留言评论