在我们气象领域,对数据进行批处理随处可见,尤其是在处理模式数据的时候。为了能让这个过程加速,很多大佬们提出了不同的方法,比如使用numba库进行计算、使用dask库进行并行等等,都是非常好的加速手段。但你知道嘛,其实我们只需要在批量读取数据时加上glob的一行命令,就可以得到显著加速(数据量越大加速效果越明显)!下面具体给大家演示一下。
任务
为了测试glob的显著加速效果,我们做了两组测试:一组用os库来批量读取所有的wrfout文件,一组用glob库来批量读取所有的wrfout文件,让两组实验分别做同样的数据处理:即将o3变量插值到想要的高度层上。利用%%time命令来比较两组实验各自所用的时间,代码附在文末。
结果

代码
import xarray as xr
import numpy as np
from wrf import interpz3d,destagger
import os
import glob
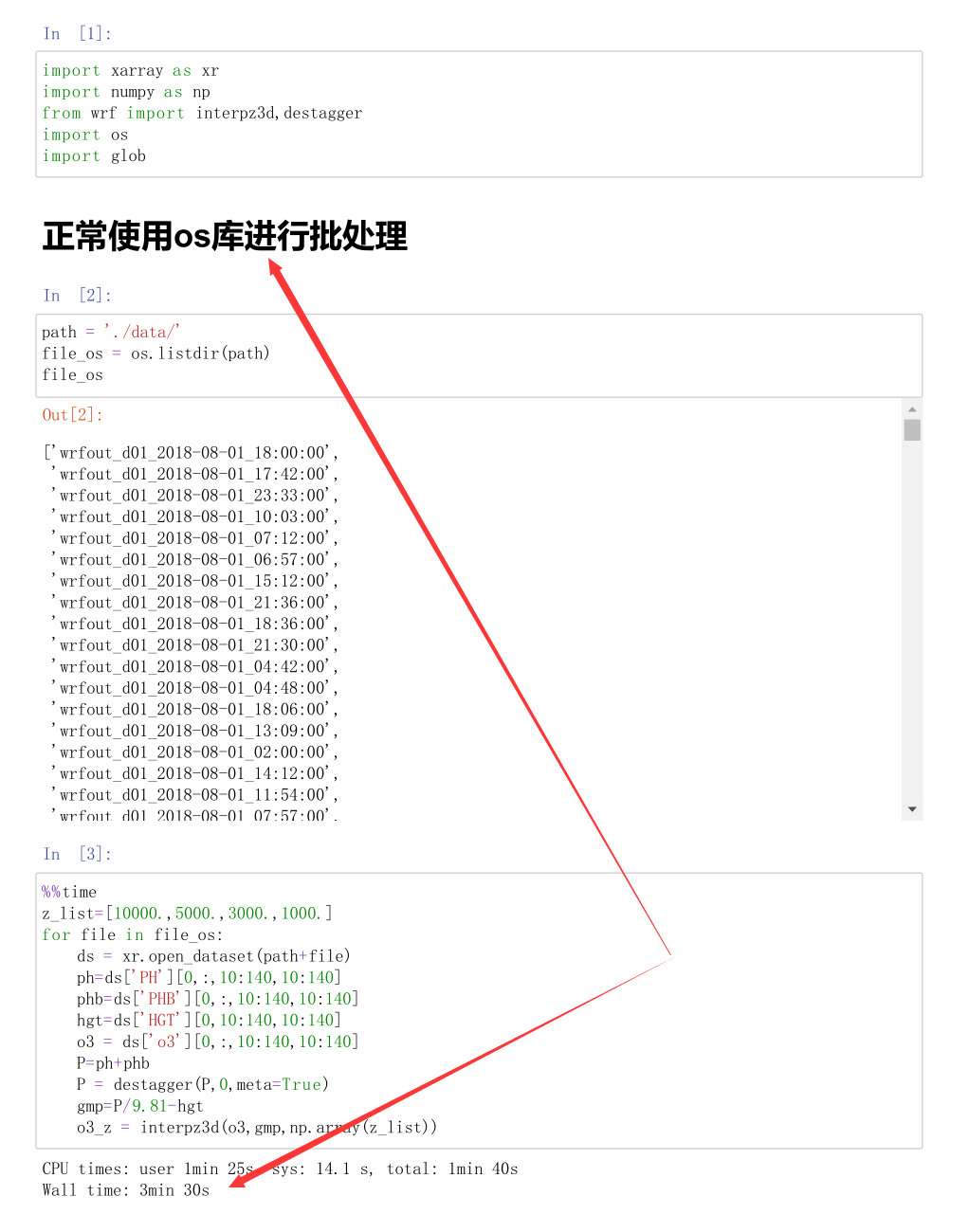
正常使用os库进行批处理
path = './data/'
file_os = os.listdir(path)
file_os
%%time
z_list=[10000.,5000.,3000.,1000.]
for file in file_os:
ds = xr.open_dataset(path+file)
ph=ds['PH'][0,:,10:140,10:140]
phb=ds['PHB'][0,:,10:140,10:140]
hgt=ds['HGT'][0,10:140,10:140]
o3 = ds['o3'][0,:,10:140,10:140]
P=ph+phb
P = destagger(P,0,meta=True)
gmp=P/9.81-hgt
o3_z = interpz3d(o3,gmp,np.array(z_list))
测试使用glob库进行批处理
file_glob = glob.glob('./data/*')
file_glob
%%time
z_list=[10000.,5000.,3000.,1000.]
for file in file_glob:
ds = xr.open_dataset(file)
ph=ds['PH'][0,:,10:140,10:140]
phb=ds['PHB'][0,:,10:140,10:140]
hgt=ds['HGT'][0,10:140,10:140]
o3 = ds['o3'][0,:,10:140,10:140]
P=ph+phb
P = destagger(P,0,meta=True)
gmp=P/9.81-hgt
o3_z = interpz3d(o3,gmp,np.array(z_list))
标签:
留言评论