点亮 ️ Star · 照亮开源之路
GitHub:https://github.com/apache/dolphinscheduler

精彩回顾
近期,初灵科技的大数据开发工程师钟霈合在社区活动的线上 Meetup 上中,给大家分享了《基于 Apache DolphinScheduler 对千亿级数据的应用实践》主题演讲。
我们对于千亿级数据量的数据同步需求,进行分析和选型后,初灵科技最终决定使用DolphinScheduler进行任务调度,同时需要周期性调度 DataX、SparkSQL 等方式进行海量数据迁移。在日常大数据工作中,利用DolphinScheduler减少日常运维工作量。
讲师介绍

钟霈合
初灵科技 大数据开发工程师
演讲大纲:
背景介绍
海量数据处理
应用场景
未来的规划
背景介绍
01 自研任务调度
我们公司前期一直是用的自研的任务调度框架,随着这个调度领域开源软件的发展,涌现了很多像海豚调度这样非常优秀的任务调度系统,而我们的需求已经到了必须要引入新的任务调度系统程度,来保证技术的更新迭代。
02 需求分析
1、支持多租户的权限控制
我们在日常工作中不止研发会进行任务的调度,其他的业务部门和厂商都可能会在DS上跑一些任务,如果没有多租户的权限控制的话,那整个集群使用起来都会非常的混乱。
2、上手简单,支持可视化任务管理
上手简单,因为我们团队内部在很多时候,开发会给到数仓/业务团队去使用,如果任务调度上手非常困难,如果需要进行大量的配置或者编写代码,相对成本就要高很多,相信在很多大数据团队都会存在这个需求,并且有些项目需要快速迭代,所以对于选型的工具必然是上手简单的。
3、支持对任务及节点状态进行监控
我们对任务调度原生监控主要有两点需求,第一是服务器的监控,可以直接通过任务调度web页面去看,第二是任务调度的监控,针对任务是否成功、执行时间等相关数据和状态能够一目了然。
4、支持较为方便的重跑、补数
我们数据有实时、周期和离线三部分的,数据特性产生了这个需求,比如对于每15分钟或者每小时的数据任务,如果不能很好的支持重跑和补数的话,对我们影响还是比较大的。
5、支持高可用HA、弹性扩容、故障容错
集群运维和故障管理方面也是需要支持的。
6、支持时间参数
有时候需要基于时间参数进行数据的ETL周期操作。
03 任务调度对比

Crontab
在Unix和类Unix系统中周期性地执行指令或脚本,用来在Linux上直接执行脚本,但只能用来运行脚本。
不支持多租户权限管理、平台管理、分发执行等功能,在我们公司中的应用是在一些特点服务器跑一些临时的脚本。
并且原生Crontab只支持分钟级别的调度,不支持重跑。
Rundeck
Rundeck是一个基于Java和Grails的开源的运维自动化工具,提供了Web管理界面进行操作,同时提供命令行工具和WebAPI的访问控制方式。
像Ansible之类的工具一样,Rundeck能够帮助开发和运维人员更好地管理各个节点。
分为企业版和免费版,免费版对于我们来说功能还是有点欠缺的。
Quartz
Quartz 是一款开源且丰富特性的任务调度库,是基于Java实现的任务调度框架,能够集成与任何的java应用。
需要使用Java编程语言编写任务调度,这对于非研发团队而言,是无法去推广使用的。
xxl-job
是一款国产开发的轻量级分布式调度工具,但功能比海豚调度少。
其不依赖于大数据组件,而是依赖于MySQL,和海豚调度的依赖项是一样的。
Elastic-Job
是基于Quartz 二次开发的弹性分布式任务调度系统,初衷是面向高并发且复杂的任务。
设计理念是无中心化的,通过ZooKeeper的选举机制选举出主服务器,如果主服务器挂了,会重新选举新的主服务器。
因此elasticjob具有良好的扩展性和可用性,但是使用和运维有一定的复杂度。
Azkaban
Azkaban也是一个轻量级的任务调度框架,但其缺点是可视化支持不好,任务必须通过打一个zip包来进行实现,不是很方便。
AirFlow
AirFlow是用Python写的一款任务调度系统,界面很高大上,但不符合中国人的使用习惯。
需要使用Python进行DAG图的绘制,无法做到低代码任务调度。
Oozie
是集成在Hadoop中的大数据任务调度框架,其对任务的编写是需要通过xml语言进行的。
04 选择DolphinScheduler的理由
1、部署简单,Master、Worker各司其职,可线性扩展,不依赖于大数据集群
2、对任务及节点有直观的监控,失败还是成功能够一目了然
3、任务类型支持多,DAG图决定了可视化配置及可视化任务血缘
4、甘特图和版本控制,对于大量任务来说,非常好用
5、能够很好满足工作需求
大数据平台架构
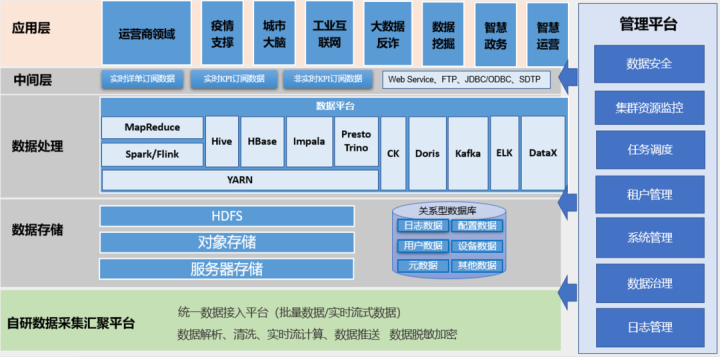
数据流图
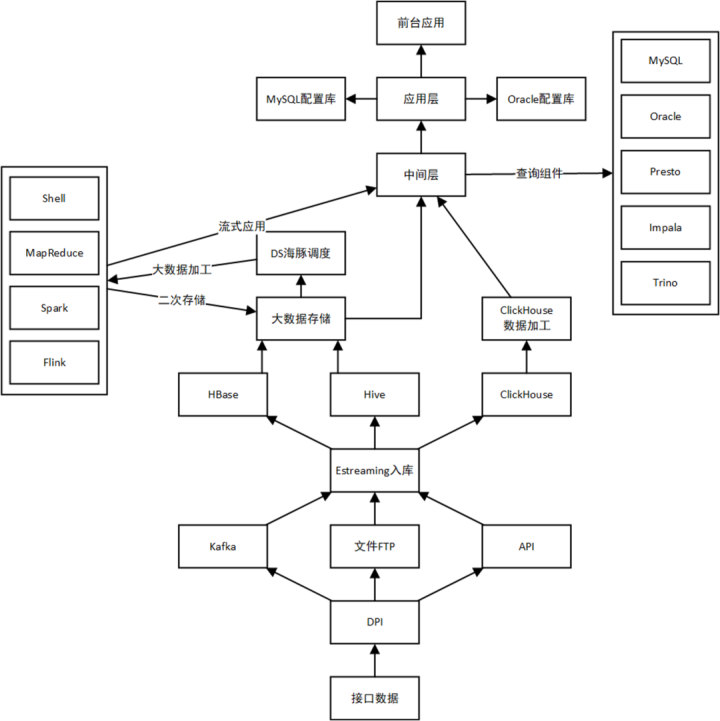
海量数据处理
01 数据需求
数据量:每天上千亿条
字段数:上百个字段,String类型居多
数据流程:在数据仓库中进行加工,加工完成的数据放入CK,应用直接查询CK的数据
存储周期:21天~60天
查询响应:对于部分字段需要秒级响应
02 数据同步选型

Sqoop
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,在DolphinScheduler上也集成了Sqoop的任务调度,但是对于从Hive到ClickHouse的需求,Sqoop是无法支持的。
Flink
通过DS调度Flink任务进行或者直接构建一套以Flink为主的实时流计算框架,对于这个需求,不仅要搭建一套计算框架,还要加上Kafka做消息队列,除此之外有增加额外的资源开销。
其次需要编写程序,这对于后面的运维团队是不方便的。
最后我们主要的场景是离线,单比较吞吐量的话,不如考虑使用Spark。
Spark&SparkSQL
在不考虑环境及资源的情况下,Spark确实是最优选择,因为我们的数据加工也是用的SparkSQL,那现在的情况就是对于数据同步来说有两种方式去做。
第一种是加工出来的数据不持久化存储,直接通过网络IO往ClickHouse里面去写,这一种方式对于服务器资源的开销是最小的,但是其风险也是最大的,因为加工出来的数据不落盘,在数据同步或者是ClickHouse存储中发现异常,就必须要进行重新加工,但是下面dws、dwd的数据是14天清理一次,所以不落盘这种方式就需要再进行考虑。
第二种方式是加工出来的数据放到Hive中,再使用SparkSQL进行同步,只是这种的话,需要耗费更多的Yarn资源量,所以在一期工程中,因为资源量的限制,我们并没有使用SparkSQL来作为数据同步方案,但是在二期工程中,得到了扩容的集群是完全足够的,我们就将数据加工和数据同步全部更换为了SparkSQL。
SeaTunnel
SeaTunnel是Spark和Flink上做了一层包装,将自身的配置文件转换为Spark和Flink的任务在Yarn上跑,实现的话也是通过各种配置文件去做。
对于这个场景来说,SeaTunnel需要耗费Yarn资源。
DataX
所以经过多方面的调研,最终选择一期工程使用DataX来作为数据通过工具,并使用DolphinScheduler来进行周期调度。
03 ClickHouse优化
在搞定数据加工和数据同步架构之后,就需要进行ClickHouse的优化。
写入本地表
在整个集群中最开始是用的Nginx负载均衡写,这个过程中我们发现效果不理想,也尝试了用分布式表写,效果提升也不明显,后面的话我们的解决方案就是调整写入本地表,整个集群有多台设备,分别写到各个CK节点的本地表,然后查询的时候就查分布式表。
使用MergeTree表引擎家族
ClickHouse的一大核心就是MergeTree表引擎,社区也是将基于MergeTree表引擎的优化作为一个重点工作。
我们在CK中是使用的ReplicatedMergeTree作为数据表的本地表引擎,使用的ReplicatedReplacingMergeTree作为从MySQL迁移过来的数据字典的表引擎。
二级索引优化
第一个的优化点是二级索引的优化,我们把二级索引从minmax替换到了bloom_filter,并将索引粒度更改到了32768。
在二级索引方面的话我们尝试过minmax、intHash64、halfMD5、farmHash64等,但是对于我们的数据而言的话,要么就是查询慢,要么就是入数据慢,后来改为了bloom_filter之后写入才平衡了。
小文件优化
在数据加工后,出现的小文件非常多,加工出来的小文件都是5M左右,所以在SparkSQL中添加了参数,重新加工的文件就是在60M~100M左右了。
set spark.sql.adaptive.enabled=true;
set spark.sql.adaptive.shuffle.targetPostShuffleInputSize=256000000;
参数优化
CK的优化参数非常多,除了基础的参数外,在二级索引调整为布隆过滤器后,写入CK的parts就比原来多了,在这个时候调整CK的parts参数,使其可以正常运行,但是这个参数会稍微影响一下CK查询的性能,对于我们来说,数据都放不进去,再查询也就没有用了。
parts_to_delay_insert:200000
此外还可以添加background_pool_size参数(我们没有用)。
Zookeeper优化
对于ClickHouse多分片多副本集群模式来说,Zookeeper是最大的性能瓶颈点。
在不改动源码的情况下,我们做了如下的优化:
调整MaxSessionTimeout参数,加大Zookeeper会话最大超时时间
在Zookeeper中将dataLogDir、dataDir目录分离
单独部署一套CK集群专供ClickHouse使用,磁盘选择超过1T,然后给的是SSD盘
04 海量数据处理架构
一期技术架构
Hive数仓架构——Hive——SparkSQL——DataX——DataX Web——DolphinScheduler——ClickHouse
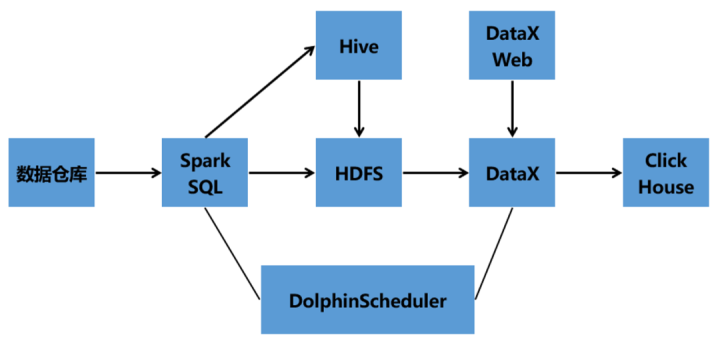
二期架构1
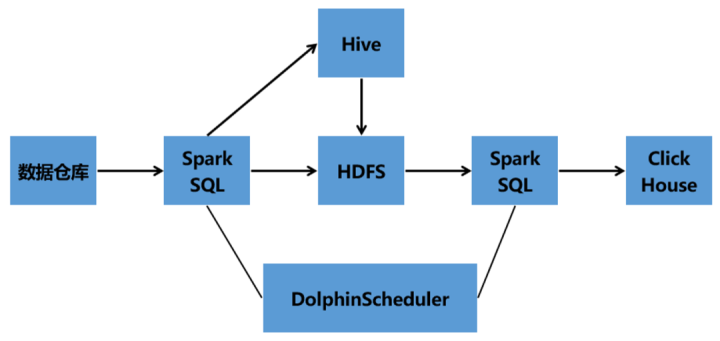
二期架构2
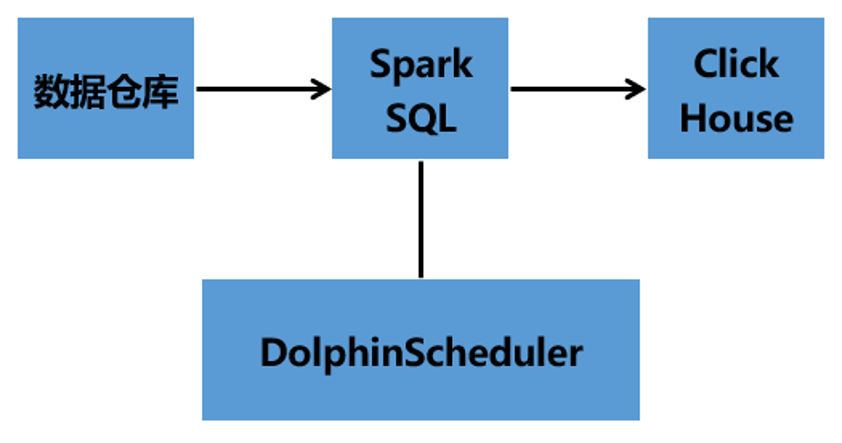
05 数据同步操作
DataX技术原理
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。

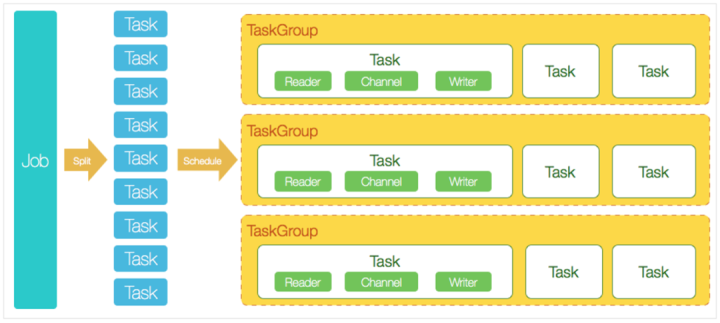
DataX在使用上比较简单,两部分一个Reader和一个Writer,在配置上面的话主要也是针对这两部分进行配置。
DataX支持的插件非常多,除了官方已经打进包里面直接可以使用的插件,还可以自己从Github上面下载源码进行Maven编译,像ClickHouse、Starrocks的writer插件都需要这么去做。
06 DataX在DS中的应用
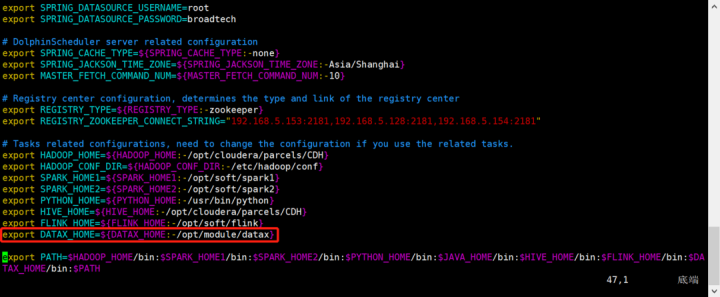
使用DataX需要在dolphinscheduler_env.sh文件中去指定datax的路径。
export DATAX_HOME=${DATAX_HOME:-/opt/module/datax}
之后DataX可以有三种方式去使用。
第一种方式的使用“自定义模板”,然后在自定义模板中去编写DataX的json语句:

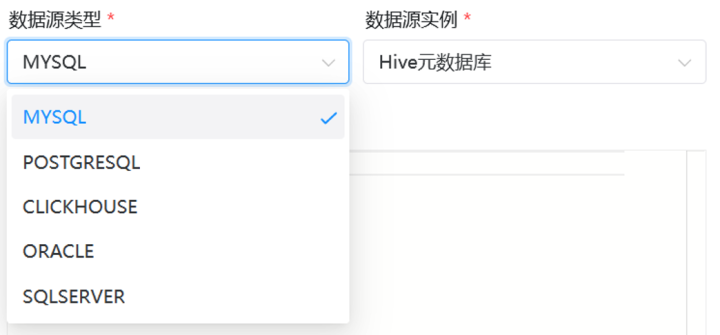
第二种方式是通过DS自带的选型,然后编写SQL去使用DataX,在DS中可以通过可视化界面配置的插件有_MySQL、PostgreSQL、ClickHouse、Oracle、SQLServer:_
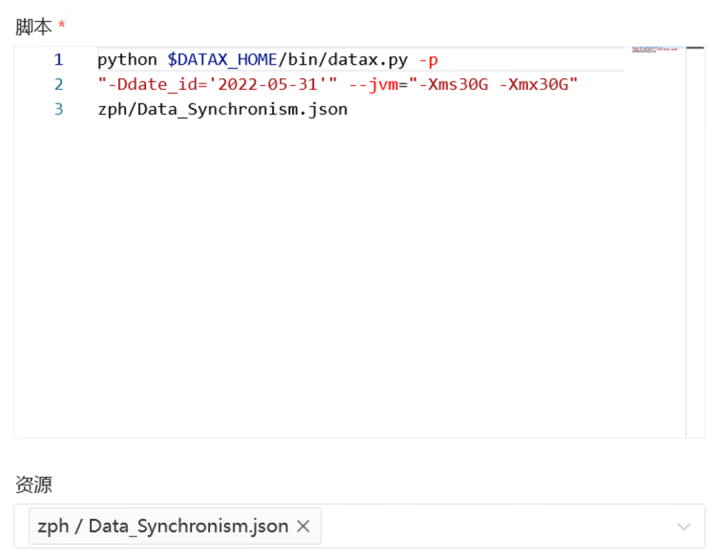
第三种方式是在DS中建立shell任务,然后通过shell去调用部署在服务器上的DataX脚本,并且要把脚本放到DS的资源中心里面:
第一种方式对我们来说是最方便也是适配性最强的方式,第二种和第三种的话就要根据情况去使用了。
07 DataX的使用
在DataX内部对每个Channel会有严格的速度控制,分两种,一种是控制每秒同步的记录数,另外一种是每秒同步的字节数,默认的速度限制是1MB/s, 可以根据具体硬件情况设置这个byte速度或者record速度,一般设置byte速度。
我们的channel的话是根据每个任务的数据量条数、大小进行多次调优后得出的,这个要根据自己的数据情况进行适配,我的任务最大的一个数据量配置的是总的record限速是300M/s,单个channel的record限速是10M/s。
{
但是channel并不是越大越好,过分大反而会影响服务器的性能,会经常的报GC,一报GC的话,性能就会下降。
一般我们的服务器,配置了上面的参数后,一个任务没事,如果多个DataX任务同时在一台服务器上跑的话并且JVM设置得过小的话,一般5分钟会报一次GC。
根据刚才的调控,明显一个DataX任务中的channel数是增多了的,这就表示占用的内存也会增加,因为DataX作为数据交换通道,在内存中会缓存较多的数据。
在DataX中会有一个Buffer作为临时的内存交换的缓存区,而且在Reader和Writer中,也会存在一些Buffer用来缓存数据,JVM报GC的话主要也是在这上面报,所以我们需要根据配置调整JVM的参数。
一般我的任务参数会用DS的参数进行控制,如下所示,一般设置为4G~16G,这个的话得根据硬件的性能来决定。
$DATAX_HOME:/opt/beh/core/datax/pybin/datax.py --jvm="-Xms8G -Xms8G" -p"-Da=1"
将内存和CPU调优做了之后,再往下就是对Reader和Writer的基础配置,比如说HDFS路径、Kerberos相关、字段的映射关系、CK的库表等等。
最后一部分就是我们在使用的时候,发现即使对CK做了优化,还是会报parts过多的错误,经过排查,DataX的ClickHouse Writer是通过JDBC远程连接到ClickHouse数据库,然后利用ClickHouse暴露的insert接口将数据insert into到ClickHouse。根据ClickHouse特性,每一次的insert into都是一个parts,所以不能一条数据就insert一次,必须大批量的插入ClickHouse,这也是官方推荐的。
所以我们对DataX的batchSize进行了优化,优化参数如下:
"batchSize": 100000,
应用场景
01 元数据备份
使用DS周期性备份Hive元数据、CDH元数据、HDP元数据、DS自己的元数据,并将其上传到HDFS中进行保存。
02 任务调度
对Shell、SparkSQL、Spark、DataX、Flink等任务进行调度,目前的工作点主要是分为新加任务和老任务迁移。
新加任务的话就是新项目的任务我们会推动业务部门及其余研发中心将任务上到DS调度平台,老任务迁移的话阻力比较大,就是把之前的离线、流式和shell任务给迁移到DS上,迁移的过程中将一些老旧的MR代码改为Spark或者Flink后放到DS上来跑。
03 甘特图

04 数据清理
主要就是针对部分数据有存放周期的,需要周期对Hive、HDFS,还有一些服务器上的日志进行周期清理。
未来的规划
1、从某一个任务调度系统往DS进行任务迁移的工具,半自动化,帮助推进DS的在调度领域的应用。
2、DS集群部署、升级工具,减少运维工作量。
3、从定制化监控转变为插件式监控,从高代码到低代码的转变,时监控告警更加灵活,及早发现节点、工作流、数据库、任务等的问题。
4、二次开发,增加只读场景、回收站功能,增多判断条件及功能,资源批量上传等,助力大数据。
5、集成API网关功能,对协议适配、服务管理、限流熔断、认证授权、接口请求等进行一站式操作。
我的分享就到这里,感谢!感兴趣的朋友可以进入社区跟我讨论,添加社区小助手即可拉入中国区用户组~
最后非常欢迎大家加入 DolphinScheduler 大家庭,融入开源世界!
我们鼓励任何形式的参与社区,最终成为 Committer 或 PMC,如:
将遇到的问题通过 GitHub 上 issue 的形式反馈出来。
回答别人遇到的 issue 问题。
帮助完善文档。
帮助项目增加测试用例。
为代码添加注释。
提交修复 Bug 或者 Feature 的 PR。
发表应用案例实践、调度流程分析或者与调度相关的技术文章。
帮助推广 DolphinScheduler,参与技术大会或者 meetup 的分享等。
欢迎加入贡献的队伍,加入开源从提交第一个 PR 开始。
- 比如添加代码注释或找到带有 ”easy to fix” 标记或一些非常简单的 issue(拼写错误等) 等等,先通过第一个简单的 PR 熟悉提交流程。
注:贡献不仅仅限于 PR 哈,对促进项目发展的都是贡献。
相信参与 DolphinScheduler,一定会让您从开源中受益!
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。
参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A"volunteer+wanted"
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
标签:
留言评论