论文信息
论文标题:Rumor Detection on Social Media with Event Augmentations论文作者:Zhenyu He, Ce Li, Fan Zhou, Yi Yang论文来源:2021,SIGIR论文地址:download论文代码:download
1 Introduction
现有的深度学习方法取得了巨大的成功,但是这些方法需要大量可靠的标记数据集来训练,这是耗时和数据低效的。为此,本文提出了 RDEA ,通过事件增强在社交媒体上的谣言检测(RDEA),该方案创新地集成了三种增强策略,通过修改回复属性和事件结构,提取有意义的谣言传播模式,并学习用户参与的内在表示。
贡献:
- 涉及了三种可解释的数据增强策略,这在谣言时间图数据中没有得到充分的探索;
- 在谣言数据集中使用对比自监督的方法进行预训练;
- REDA 远高于其他监督学习方法;
2 Methodology
总体框架如下:
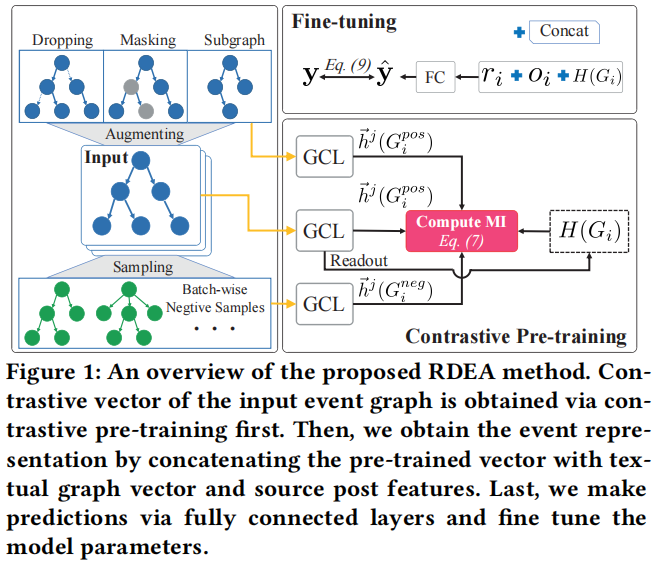
主要包括三个模块:
- event graph data augmentation
- contrastive pre-training
- model fne-tuning
2.1 Event Augmentation
谣言事件中存在两种用户:
- malicious users
- naive users
malicious users 故意传播虚假信息,nvaive users 无意中帮助了 malicious users 传播虚假信息,所以 mask node 是可行的。
给定除 root node 的节点特征矩阵 $E^{-r} \in \mathbb{R}^{(|\mathcal{V}|-1) \times d}$,以及一个 mask rate $p_{m}$,mask 后的节点特征矩阵为:
$E_{\text {mask }}^{-r}=\mathrm{M} \odot E^{-r} $
其中,$M \in\{0,1\}^{(|\mathcal{V}|-1) \times d}$ 代表着 mask matrix,随机删除 $ (|\mathcal{V}|-1) \times p_{m}$ 行节点特征矩阵。
2.2 Subgraph
用户在早期阶段通常是支持真实谣言的,所以,在模型训练时,如果过多的访问谣言事件的整个生命周期,将阻碍早期谣言检测的准确性,所以本文采取随机游走生成谣言事件的子图 $G_{i_sub}$。
2.3 Edge dropping
形式上,给定一个邻接矩阵 $A$ 和 $N_{e}$ 条边和丢弃率 $p_{d}$,应用 DropEdge 后的邻接矩阵 $A_{d r o p}$,其计算方法如下:
$A_{d r o p}=A-A^{\prime}$
其中,$A^{\prime}$ 是随机采样 $N_{e} \times p_{d} $ 条边的邻接矩阵。
2.2 Contrastive Pre-training
在本节将介绍如何通过在输入事件和增强事件之间的对比预训练来获得互信息。
形式上,对于 node $j$ 和 event graph $G$,self-supervised learning 过程如下:
$\begin{array}{l}h_{j}^{(k)} &=&\operatorname{GCL}\left(h_{j}^{(k-1)}\right) \\h^{j} &=&\operatorname{CONCAT}\left(\left\{h_{j}^{(k)}\right\}_{k=1}^{K}\right)\\H(G) &=&\operatorname{READOUT}\left(\left\{h^{j}\right\}_{j=1}^{|\mathcal{V}|}\right)\end{array}$
其中,$h_{j}^{(k)}$ 是节点在第 $k$ 层的特征向量。GCL 是 graph convolutional encoder ,$h^{j}$ 是通过将 GCL 所有层的特征向量汇总为一个特征向量,该特征向量捕获以每个节点为中心的不同尺度信息,$H(G)$ 是应用 READOUT 函数的给定事件图的全局表示。本文并选择 GIN 作为 GCL 和 mean 作为 READOUT 函数 。对比预训练的目标是使谣言传播图数据集上的互信息(MI)最大化,其计算方法为:
${\large \begin{aligned}I_{\psi}\left(h^{j}(G) ; H(G)\right):=& \mathbb{E}\left[-\operatorname{sp}\left(-T_{\psi}\left(\vec{h}^{j}\left(G_{i}^{\text {pos }}\right), H\left(G_{i}\right)\right)\right)\right] \\&-\mathbb{E}\left[\operatorname{sp}\left(T_{\psi}\left(\vec{h}^{j}\left(G_{i}^{n e g}\right), H\left(G_{i}\right)\right)\right)\right]\end{aligned}} $
其中,$I_{\psi}$ 为互信息估计器,$T_{\psi}$ 为鉴别器(discriminator),$G_{i}$ 是输入 event 的 graph,$G_{i}^{\text {pos }}$ 是 $G_{i}$ 的 positive sample,$G_{i}^{\text {neg }}$ 是 $G_{i}$ 的负样本,$s p(z)=\log \left(1+e^{z}\right)$ 是 softplus function。对于正样本,可以是 $G_{i}\left(E_{\text {mask }}^{-r}\right)$,$G_{i_{-} s u b$,$G_{i}\left(A_{d r o p}\right)$,负样本是 一个 batch 中其他 event graph 的局部表示。
在对 event graph 进行对比预训练后,我们得到了 input event graph $G_{i}$ 的预训练的向量 $H\left(G_{i}\right)$。然后,对于一个 event $C_{i}=\left[r_{i}, x_{1}^{i}, x_{2}^{i}, \cdots, x_{\left|\mathcal{V}_{i}\right|-1}^{i}, G_{i}\right]$,通过平均所有相关的回复帖子和源帖子的原始特征 $o_{i}=\frac{1}{n_{i}}\left(\sum_{j=1}^{\left|\mathcal{V}_{i}\right|-1} x_{j}^{i}+r_{i}\right)$,我们得到了文本图向量 $o_{i}$。为了强调 source post,将 contrastive vector、textual graph vector 和source post features 合并为:
$\mathbf{S}_{i}=\mathbf{C O N C A T}\left(H\left(G_{i}\right), o_{i}, r_{i}\right)$
2.3 Fine tuning
预训练使用了文本特征,得到了预训练的 event representation,并包含了原始特征和 source post 信息,在 fine-tune 阶段,使用预训练的参数初始化参数,并使用标签训练模型:
将上述生成的 $s_{i}$ 通过全连接层进行分类:
$\hat{\mathbf{y}}_{i}=\operatorname{softmax}\left(F C\left(\mathbf{S}_{i}\right)\right)$
最后采用交叉熵损失:
$\mathcal{L}(Y, \hat{Y})=\sum_{i=1}^{|C|} \mathbf{y}_{i} \log \hat{\mathbf{y}}_{i}+\lambda\|\Theta\|_{2}^{2}$
其中,$\|\Theta\|_{2}^{2}$ 代表 $L_{2}$ 正则化,$\Theta$ 代表模型参数,$\lambda$ 是 trade-off 系数。
3 Experiments
- DTC [3]: A rumor detection approach applying decision tree that utilizes tweet features to obtain information credibility.
- SVM-TS [10]: A linear SVM-based time-series model that leverages handcrafted features to make predictions.
- RvNN [11]: A recursive tree-structured model with GRU units that learn rumor representations via the tree structure.
- PPC_RNN+CNN [8]: A rumor detection model combining RNN and CNN for early-stage rumor detection, which learns the rumor representations by modeling user and source tweets.
- Bi-GCN [2]: using directed GCN, which learns the rumor representations through Bi-directional propagation structure.
3.2 Performance Comparison

3.3 Ablation study

-R represent our model without root feature enhancement -T represent our model without textual graph -A represent our model without event augmentation -M represent our model without mutual information
3.4 Limited labeled data
Figure 3 显示了当标签分数变化时的性能:
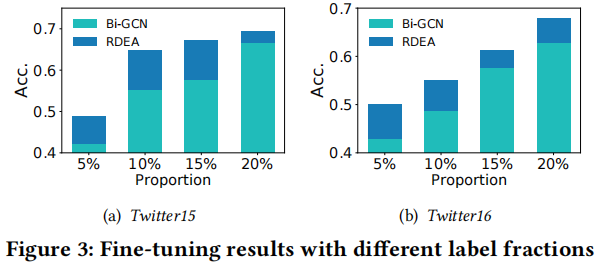
我们观察到,RDEA 对这两个数据集都比 Bi-GCN 更具有标签敏感性。此外,标签越少,改进幅度越大,说明RDEA的鲁棒性和数据有效性。
3.5 Early Rumor Detection

标签: # 谣言检测
留言评论