1、Lambda表达式
Lambda 是一个匿名函数,我们可以把 Lambda 表达式理解为是一段可以传递的代码(将代码像数据一样进行传递)。使用它可以写出更简洁、更灵活的代码。作为一种更紧凑的代码风格,使Java的语言表达能力得到了提升。
1.1 语法组成
- 操作符为" -> " ,被称为 Lambda 操作符或箭头操作符;
- 将 Lambda 分为两个部分:
- 左侧:指定了 Lambda 表达式需要的参数列表;
- 右侧:指定了 Lambda 体,是抽象方法的实现逻辑,也即Lambda 表达式要执行的功能。
1.2 基本用法
1.2.1 未使用和使用Lambda表达式的区别
@Slf4j
public class TestLambda {
//未使用和使用lambda表达式,对比
static void testRunLambdaContrast(){
// 不使用lambda表达式,创建一个线程
Runnable runnable1 = new Runnable() {
@Override
public void run() {
log.info("------ 不使用lambda表达式,创建一个线程 ------");
}
};
// 启动线程
new Thread(runnable1).start();
// 使用lambda表达式,创建一个线程
Runnable runnable2 = () -> log.info("------ 使用lambda表达式,创建一个线程 ------");
// 启动线程2
new Thread(runnable2).start();
}
public static void main(String[] args) {
//测试 未使用和使用lambda表达式,对比
testRunLambdaContrast();
}
}
总结:未使用和使用Lambda表达式都可以实现抽象方法,但是使用Lambda方法后会更加简洁;
1.2.2 带一个参数没有返回值
1.2.2.1 带一个参数没有返回值 标准写法
// 借助java8中 消费型函数式接口,讲解基本用法
// 不使用lambda表达式实现
Consumer<String> consumer1 = new Consumer<String>() {
@Override
public void accept(String s) {
log.info("------ 不使用lambda表达式,实现Consumer1接口,消费数据:{} ------",s);
}
};
// 使用消费型接口1
consumer1.accept("kh96正在学习lambda表达式,标准写法");
// 使用lambda表达式,用法:带 1 个参数,没有返回值,标准写法
Consumer<String> consumer2 = (String s) -> {
log.info("------ 使用lambda表达式,实现Consumer2接口,消费数据:{} ------",s);
};
// 使用消费型接口2
consumer2.accept("kh96正在学习lambda表达式,标准写法");
1.2.2.2 简化写法:一个参数,可以省略类型声明
//一个参数,可以省略类型声明
Consumer<String> consumer3 = (s) -> {
log.info("------ 使用lambda表达式,实现Consumer3接口,消费数据:{} ------",s);
};
consumer3.accept("kh96正在学习lambda表达式,一个参数,可以省略类型声明");
1.2.2.3 简化写法:一个参数,可以省略小括号(没有参数,多个参数不能省略)
//一个参数,可以省略小括号(没有参数,多个参数不能省略)
Consumer<String> consumer4 = s -> {
log.info("------ 使用lambda表达式,实现Consumer4接口,消费数据:{} ------",s);
};
consumer4.accept("kh96正在学习lambda表达式,一个参数,可以省略小括号");
1.2.2.4 简化写法:实现只有一条语句,可以省略大括号(有多条语句,不可以省略)
//实现只有一条语句,可以省略大括号(有多条语句,不可以省略)
Consumer<String> consumer5 = s -> log.info("------ 使用lambda表达式,实现Consumer3接口,消费数据:{} ------",s);
consumer5.accept("kh96正在学习lambda表达式,实现只有一条语句,可以省略大括号");
1.2.2.5 简化写法:实现有多条语句,不可以省略大括号
//实现有多条语句,不可以省略大括号
Consumer<String> consumer6 = s -> {
log.info("------ 使用lambda表达式,实现Consumer3接口,消费数据:{} ------",s);
log.info("------ 使用lambda表达式,实现Consumer3接口,消费数据:{} ------",s);
};
consumer6.accept("kh96正在学习lambda表达式,实现有多条语句,不可以省略大括号");
1.2.3 带多个参数,有返回值
1.2.3.1 未使用 lambda 表达式,用法:带多个参数,有返回值
// 借助Comparator接口,讲解多个参数
Comparator<Integer> comparator1 = new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1.compareTo(o2);
}
};
// 未使用lambda表达式,用法:带多个参数,有返回值
log.info("------ 不使用lambda表达式,实现Comparator接口,比较12,23的大小:{} ------",comparator1.compare(12,23));// 小于 -1,大于 1,等于 0
1.2.3.2 简化写法:省略参数类型,但是不可以省略小括号,一条语句省略大括号,跟返回值无关(不用手动加return)
//省略参数类型,但是不可以省略小括号,一条语句省略大括号,跟返回值无关(不用手动加return)
Comparator<Integer> comparator2 = (o1,o2) -> o1.compareTo(o2);
log.info("------ 使用lambda表达式,实现Comparator接口,比较23,12的大小:{} ------",comparator2.compare(23,12));// 大于 1
1.2.3.3 简化写法:多条语句不可以省略大括号,带返回值(需手动加return)
//多条语句不可以省略大括号,带返回值(需手动加return)
Comparator<Integer> comparator3 = (o1,o2) -> {
log.info("------ 比较原数值为:{},{}",o1,o2);
return o1.compareTo(o2);
};
log.info("------ 使用lambda表达式,实现Comparator接口,比较22,22的大小:{} ------",comparator3.compare(22,22));// 等于 0
1.3 java8中提供的函数式接口
1.3.1 消费型接口 Consumer (方法有一个参数,没有返回值)
1.3.1.1 自定义方法 (使用接口的 void accept(T t) )
//自定义方法,带有一个消费型接口参数,可以实现一个方法,处理不同的业务场景
static void useConsumer(Double salary,Consumer<Double> consumerDate){
consumerDate.accept(salary);
}
1.3.1.2 方法调用
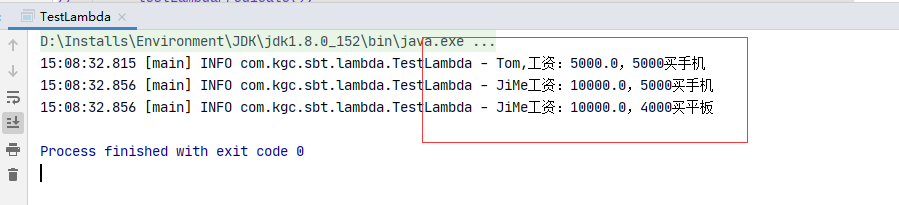
static void testLambdaConsumer(){
//场景,同一个接口,有多个实现,以前,必须要创建接口的多个实现类,现在使用lambda,把接口的实现交给调用方法传递
//实现1:Tom发了5000工资,去买手机,模拟接口的第一个实现
//以前,必须提供接口的实现类对象
useConsumer(5000.0,salary -> log.info("Tom,工资:{},5000买手机",salary));
//实现1:Tom发了10000工资,去买手机,买平板,模拟接口的第二个实现
//以前,必须提供接口的 两个 实现类对象
useConsumer(10000.0,slary -> {
log.info("JiMe工资:{},5000买手机",slary);
log.info("JiMe工资:{},4000买平板",slary);
});
}
1.3.1.3 测试结果
1.3.2 供给型接口 Supplier(方法没有参数,可以返回任意类型的结果)
1.3.2.1 自定义方法 (使用接口的 T get() )
//带一个供给型参数,可以实现同一个方法,处理实现同一个方法,处理不同的业务场景,给的数据不同,返回的结果不同
static String useSupplier(Double salary, Supplier<Double> supplierData){
//判断是否高薪的逻辑
if(salary > supplierData.get()){
return "高薪";
}
return "底薪";
}
1.3.2.2 方法调用
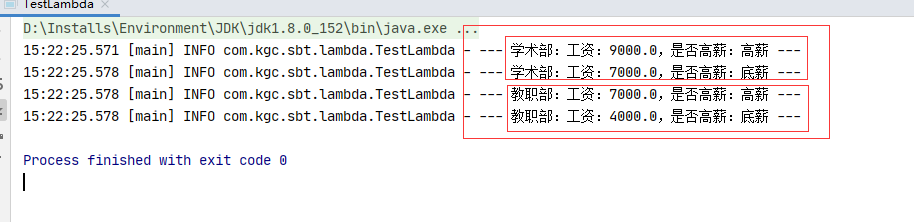
static void testLambdaSupplier(){
//场景:不同的部门,针对高薪的判断条件不同,比如:学术部高于8000算高薪,教职部门高于5000算高薪
//以前的写法:根据不同的不同,增加if...else 判断,随着部门的增加,你分的判断会越来越复杂
log.info("--- 学术部:工资:{},是否高薪:{} ---",9000.0,useSupplier(9000.0,() -> 8000.0));
log.info("--- 学术部:工资:{},是否高薪:{} ---",7000.0,useSupplier(7000.0,() -> 8000.0));
log.info("--- 教职部:工资:{},是否高薪:{} ---",7000.0,useSupplier(7000.0,() -> 5000.0));
log.info("--- 教职部:工资:{},是否高薪:{} ---",4000.0,useSupplier(7000.0,() -> 5000.0));
}
1.3.2.3 测试结果
1.3.3 断言型接口 Predicate(方法有一个参数,有返回值-布尔类型)
1.3.3.1 自定义方法 (使用接口的 boolean test(T t) )
//将判断条件交给调用方法
static List<String> userPredicate(List<String> nameList, Predicate<String> predicateData){
//定义要返回的姓名集合
List<String> returnNameList = new ArrayList();
//使用断言型接口,根据传过来的实现,返回不同的结果
nameList.forEach(name ->{
//调用断言型接口的test方法,进行挑选数据
if(predicateData.test(name)){
returnNameList.add(name);
}
});
//返回符合条件的集合数据
return returnNameList;
}
1.3.3.2 方法调用
static void testLambdaPredicate(){
//使用场景
//已知姓名集合,根据不同的场景,筛选不同的姓名结果
List<String> nameList = Arrays.asList("Lilei","Hanmeinei","lisi","zhangsan","xiaolong","xiaohu");
//获取姓名集合中所有包含n的姓名集合,可以定义第一个方法,实现
//获取集合中包含i 或者a的姓名集合,可以定义第二个方法,实现
//随着规则的改变,实现的方法越来越多,去简化,所有的方法就是判断规则不同,其他都一样,可以使用断言型接口,优化
//获取姓名集合中所有包含n的姓名集合
List<String> nameList_n = userPredicate(nameList,name -> name.contains("n"));
log.info("姓名集合中所有包含n的姓名集合:{}",nameList_n);
//获取集合中包含i 或者a的姓名集合
List<String> nameList_i_a = userPredicate(nameList,name -> name.contains("i") || name.contains("a"));
log.info("获取集合中包含i 或者a的姓名集合:{}",nameList_i_a);
}
1.3.3.3 测试结果

1.3.4 函数接口 Function,有任意类型参数,有任意类型返回值
1.3.4.1 自定义方法(使用接口的R apply(T t) ) 和 方法调用
static void testLambdaFunction(){
Function<Integer,Double> function = num -> new Random().nextInt(num)*1.0;
log.info("--- 使用函数型接口,接收整数:{},返回随机浮点型结果:{} ---",96,function.apply(96));
}
1.3.4.2 测试结果

1.3.5 自定义函数式接口
// 自定义的函数式接口:带一个任意类型参数,返回String类型值
// 定义:凡是一个接口中,只有一个抽象方法,那这个接口就是函数式接口,可以别注解 //@FunctionalInterface修饰
@FunctionalInterface
public interface MyFunctionInterface<T> {
//函数式接口中的唯一抽象方法
String helloKh96(T t);
//可以增加默认方法,允许的
default void hiKH96(){
//默认方法
}
}
2、StreamAPI
2.1 创建流 有限流 和 无限流
2.1.1 有限流
//有限流, 输出1,3,5,7,9 的平方
log.info("\n----- 输出1,3,5,7,9 的平方 -----");
Stream.of(1,3,5,7,9).forEach(num -> System.out.print(num * num + ";"));
测试结果:

2.1.2 无线流
2.1.2.1 iterate
//无限流:输出前18个奇数
log.info("\n ----- 输出前18个奇数 ------");
Stream.iterate(1,n -> n+2).limit(10).forEach(num -> System.out.print(num + ";"));
2.1.2.2 generate
//无限流:输出10个随机数
log.info("\n ----- 输出前18个随机数 ------");
Stream.generate(() -> new Random().nextInt(100)).limit(10).forEach(num -> System.out.print(num+";"));
测试结果:

2.2 创建流 基于数组 和 集合
2.2.1 基于数组
//基于数组
int[] nums = {66,99,44,11,22,55,77,88};
//通过Arrays工具类提供的stream 方法
int min = Arrays.stream(nums).min().getAsInt();
int max = Arrays.stream(nums).max().getAsInt();
log.info("\n ------ 数组最小值为 :{} --------",min);
log.info("\n ------ 数组最大值为 :{} --------",max);
测试结果:

2.2.2 基于集合
//基于集合
List<String> nameList = Arrays.asList("Lilei","Hanmeinei","lisi","zhangsan","xiaolong","xiaohu");
//通过集合对象的stream方法
nameList.stream().map(name -> name.toLowerCase()).forEach(System.out::println);
测试结果:

2.3 流的中间操作
2.3.1 筛选和切片
2.3.1.0 数据准备
2.3.1.0.1 bean
//小说实体
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class Story {
// 编号
private Integer id;
// 书名
private String name;
// 作者
private String author;
// 价格
private Double price;
// 章节
private Integer sections;
// 分类
private String category;
}
2.3.1.0.2 StoryUtil
//小说工具类
public class StoryUtil {
public static List<Story> stories = new ArrayList<>();
static {
stories.add(Story.builder().id(101).name("斗破苍穹").author("zhangsan").price(109.9).sections(1202).category("玄幻").build());
stories.add(Story.builder().id(201).name("斗罗大陆").author("lisi").price(88.9).sections(999).category("科幻").build());
stories.add(Story.builder().id(301).name("凡人修仙传").author("wangwu").price(77.9).sections(1303).category("武侠").build());
stories.add(Story.builder().id(401).name("圣墟").author("zhuliu").price(121.9).sections(1404).category("玄幻").build());
stories.add(Story.builder().id(501).name("吞噬星空").author("sunqi").price(135.9).sections(996).category("历史").build());
stories.add(Story.builder().id(601).name("完美世界").author("zhaoba").price(66.9).sections(999).category("玄幻").build());
stories.add(Story.builder().id(701).name("大王饶命").author("qianjiu").price(135.9).sections(997).category("玄幻").build());
stories.add(Story.builder().id(801).name("大奉打更人").author("zhoushi").price(133.9).sections(1606).category("军事").build());
}
}
2.3.1.1 筛选:filter
//筛选: filter,相当于数据库中的where条件
log.info("-------------- 筛选: filter ----------------");
//查看小说集合中,价格大于100块的所有小说
StoryUtil.stories.stream().filter(story -> story.getPrice() > 100).forEach(System.out::println);
//练习:查看小说集合中,所有章节数大于1000且作者中包含n的小说
log.info("\n------- 查看小说集合中,所有章节数大于1000且作者中包含n的小说 ---------");
StoryUtil.stories.stream().filter(story -> story.getSections() > 1000 && story.getAuthor().contains("n") ).forEach(System.out::println);
测试结果1:
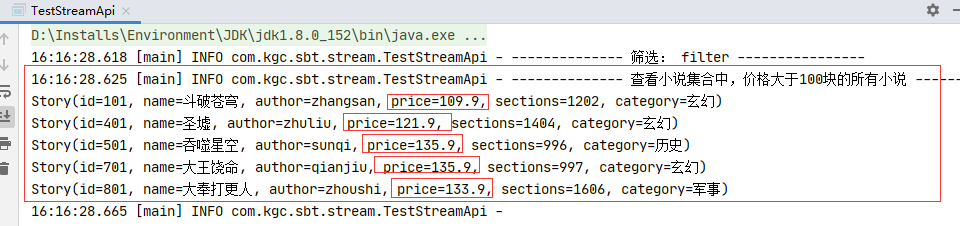
测试结果2:

2.3.1.2 截断:limit
//截断: limit 相当于数据库的limit条数
log.info("\n---------- 截断: limit ---------");
//查询小说集合,所有价格大于100的前三本
StoryUtil.stories.stream().filter(story -> story.getPrice() >100).limit(3).forEach(System.out::println);
测试结果:

2.3.1.3 跳过:skip
//跳过:skip,相当于数据库跳过数据条数
log.info("\n------------- 跳过:skip-----------------");
//查询小说集合,所有价格大于100的前三本,后的所有小说
log.info("\n------------- 查询小说集合,所有价格大于100的前三本,后的所有小说-----------------");
StoryUtil.stories.stream().filter(story -> story.getPrice() >100).skip(3).forEach(System.out::println);
测试结果:

2.3.1.4 去重:distinct
//去重:distinct,相当于数据库中的去重,了解
log.info("\n------------- 去重:distinct,相当于数据库中的去重 -----------------");
Stream.of(22,33,55,11,66,33,55,11,55).distinct().forEach(System.out::println);
测试结果:
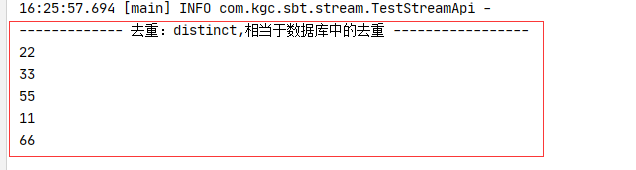
2.3.2 映射和排序
2.3.2.1 映射:map
//已知姓名集合
List<String> nameList = Arrays.asList("Lilei","Hanmeinei","lisi","zhangsan","xiaolong","xiaohu");
//映射:map,可以将流中发的元素进行转换或这提取,会自动指定的规则作用到所有的元素上,并返回一个新的流
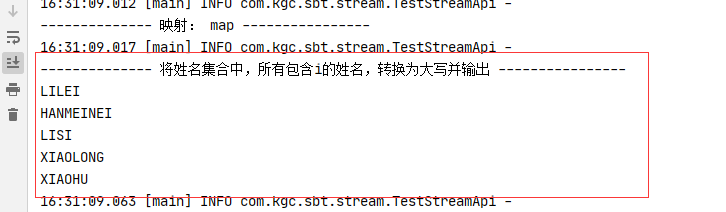
log.info("-------------- 映射: map ----------------");
//将姓名集合中,所有包含i的姓名,转换为大写并输出
//nameList.stream().filter(name -> name.contains("i")).map(name -> name.toUpperCase()).forEach(System.out::println);
nameList.stream().filter(name -> name.contains("i")).map(String::toUpperCase).forEach(System.out::println);
测试结果:
2.3.2.2 映射:map 输出单个属性
//将小说集合中,章节小于1000的作者转换为大写,输出作者
log.info("\n-------------- 将小说集合中,章节小于1000的作者转换为大写,输出作者 --------------");
//StoryUtil.stories.stream().filter(story -> story.getSections() < 1000).map(story -> story.getAuthor()).map(string -> string.toUpperCase()).forEach(System.out::println);
StoryUtil.stories.stream().filter(story -> story.getSections() < 1000).map(Story::getAuthor).map(string -> string.toUpperCase()).forEach(System.out::println);
测试结果:

2.3.2.3 映射: mapToInt
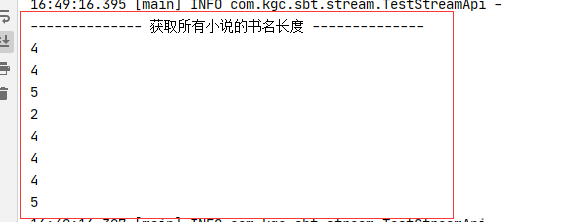
//获取所有小说的书名长度
log.info("\n-------------- 获取所有小说的书名长度 --------------");
// StoryUtil.stories.stream().map(story -> story.getName().length()).forEach(System.out::println);
StoryUtil.stories.stream().mapToInt(story -> story.getName().length()).forEach(System.out::println);
测试结果:
2.3.2.4 消费:peek
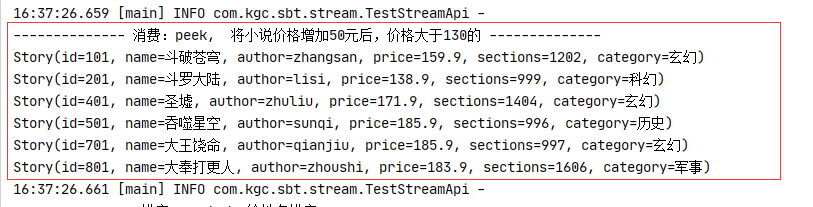
//消费:peek, 将小说价格增加50元后,价格大于130的
log.info("\n-------------- 消费:peek, 将小说价格增加50元后,价格大于130的 --------------");
StoryUtil.stories.stream().peek(story -> story.setPrice(story.getPrice()+50)).filter(story -> story.getPrice()>130).forEach(System.out::println);
测试结果:
2.3.2.5 排序:sorted
//排序:sorted ,给姓名排序
log.info("\n -------------- 排序:sorted ,给姓名排序 --------------");
nameList.stream().sorted().forEach(System.out::println);

2.3.2.6 自定义排序规则
//自定义排序,先按照价格排序,价格相同,按照章节排序
log.info("\n--------- 自定义排序,先按照价格排序,价格相同,按照章节排序 ---------");
StoryUtil.stories.stream().sorted((s1,s2)->{
int sortPrice = Double.compare(s1.getPrice(),s2.getPrice());
if(sortPrice == 0){
return Double.compare(s1.getSections(),s2.getSections());
}
return sortPrice;
}).forEach(System.out::println);
测试结果:

标签:
留言评论