布隆过滤器原理介绍
【1】概念说明
1)布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
【2】设计思想
1)BF是由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构。位数组均初始化为0,所有哈希函数都可以分别把输入数据尽量均匀地散列。
2)当要插入一个元素时,将其数据分别输入k个哈希函数,产生k个哈希值。以哈希值作为位数组中的下标,将所有k个对应的比特置为1。
3)当要查询(即判断是否存在)一个元素时,同样将其数据输入哈希函数,然后检查对应的k个比特。如果有任意一个比特为0,表明该元素一定不在集合中。如果所有比特均为1,表明该集合有(较大的)可能性在集合中。为什么不是一定在集合中呢?因为一个比特被置为1有可能会受到其他元素的影响,这就是所谓“假阳性”(false positive)。相对地,“假阴性”(false negative)在BF中是绝不会出现的。
【3】图示
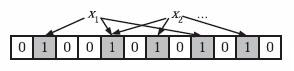
【4】优缺点
1)优点
1.不需要存储数据本身,只用比特表示,因此空间占用相对于传统方式有巨大的优势,并且能够保密数据;
2.时间效率也较高,插入和查询的时间复杂度均为O(k);
3.哈希函数之间相互独立,可以在硬件指令层面并行计算。
2)缺点
1.存在假阳性的概率,不适用于任何要求100%准确率的情境;
2.只能插入和查询元素,不能删除元素,这与产生假阳性的原因是相同的。我们可以简单地想到通过计数(即将一个比特扩展为计数值)来记录元素数,但仍然无法保证删除的元素一定在集合中。(因此只能进行重建)
guava框架如何实现布隆过滤器
【1】引入依赖
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>28.0-jre</version> </dependency>
【2】简单使用
//布隆过滤器-数字指纹存储在当前jvm当中
public class LocalBloomFilter {
private static final BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF_8),1000000,0.01);
/**
* 谷歌guava布隆过滤器
* @param id
* @return
*/
public static boolean match(String id){
return bloomFilter.mightContain(id);
}
public static void put(Long id){
bloomFilter.put(id+"");
}
}
【3】源码分析(由上面的三个主要方法看起,create方法,mightContain方法,put方法)
1)create方法深入分析
@VisibleForTesting
static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions, double fpp, Strategy strategy) {
//检测序列化器
checkNotNull(funnel);
//检测存储容量
checkArgument(expectedInsertions >= 0, "Expected insertions (%s) must be >= 0", expectedInsertions);
//容错率应该在0-1之前
checkArgument(fpp > 0.0, "False positive probability (%s) must be > 0.0", fpp);
checkArgument(fpp < 1.0, "False positive probability (%s) must be < 1.0", fpp);
//检测策略
checkNotNull(strategy);
if (expectedInsertions == 0) {
expectedInsertions = 1;
}
// 这里numBits即底下LockFreeBitArray位数组的长度,可以看到计算方式就是外部传入的期待数和容错率
long numBits = optimalNumOfBits(expectedInsertions, fpp);
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
try {
return new BloomFilter<T>(new BitArray(numBits), numHashFunctions, funnel, strategy);
} catch (IllegalArgumentException e) {
throw new IllegalArgumentException("Could not create BloomFilter of " + numBits + " bits", e);
}
}
private BloomFilter(BitArray bits, int numHashFunctions, Funnel<? super T> funnel, Strategy strategy) {
//检测hash函数个数应该在0-255之间
checkArgument(numHashFunctions > 0, "numHashFunctions (%s) must be > 0", numHashFunctions);
checkArgument(numHashFunctions <= 255, "numHashFunctions (%s) must be <= 255", numHashFunctions);
this.bits = checkNotNull(bits);
this.numHashFunctions = numHashFunctions;
this.funnel = checkNotNull(funnel);
this.strategy = checkNotNull(strategy);
}
//计算容量大小
@VisibleForTesting
static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
//计算满足条件时,应进行多少次hash函数
@VisibleForTesting
static int optimalNumOfHashFunctions(long n, long m) {
// (m / n) * log(2), but avoid truncation due to division!
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
2)mightContain方法深入分析
public boolean mightContain(T object) {
return strategy.mightContain(object, funnel, numHashFunctions, bits);
}
public <T> boolean mightContain(T object, Funnel<? super T> funnel, int numHashFunctions, BloomFilterStrategies.BitArray bits) {
long bitSize = bits.bitSize();
long hash64 = Hashing.murmur3_128().hashObject(object, funnel).asLong();
int hash1 = (int)hash64;
int hash2 = (int)(hash64 >>> 32);
for(int i = 1; i <= numHashFunctions; ++i) {
int combinedHash = hash1 + i * hash2;
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
if (!bits.get((long)combinedHash % bitSize)) {
return false;
}
}
return true;
}
3)put方法深入分析
@CanIgnoreReturnValue
public boolean put(T object) {
return strategy.put(object, funnel, numHashFunctions, bits);
}
//策略实现填入bits
public <T> boolean put(T object, Funnel<? super T> funnel, int numHashFunctions, BloomFilterStrategies.BitArray bits) {
long bitSize = bits.bitSize();
long hash64 = Hashing.murmur3_128().hashObject(object, funnel).asLong();
int hash1 = (int)hash64;
int hash2 = (int)(hash64 >>> 32);
boolean bitsChanged = false;
for(int i = 1; i <= numHashFunctions; ++i) {
int combinedHash = hash1 + i * hash2;
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
bitsChanged |= bits.set((long)combinedHash % bitSize);
}
return bitsChanged;
}
采用Redis实现布隆过滤器
【1】抽出guava框架中部分核心逻辑方法形成工具类
/**
* 算法过程:
* 1. 首先需要k个hash函数,每个函数可以把key散列成为1个整数
* 2. 初始化时,需要一个长度为n比特的数组,每个比特位初始化为0
* 3. 某个key加入集合时,用k个hash函数计算出k个散列值,并把数组中对应的比特位置为1
* 4. 判断某个key是否在集合时,用k个hash函数计算出k个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。
* @description: 布隆过滤器,摘录自Google-guava包
**/
public class BloomFilterHelper<T> {
private int numHashFunctions;
private int bitSize;
private Funnel<T> funnel;
public BloomFilterHelper(Funnel<T> funnel, int expectedInsertions, double fpp) {
Preconditions.checkArgument(funnel != null, "funnel不能为空");
this.funnel = funnel;
// 计算bit数组长度
bitSize = optimalNumOfBits(expectedInsertions, fpp);
// 计算hash方法执行次数
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
public int[] murmurHashOffset(T value) {
int[] offset = new int[numHashFunctions];
//有点类似于hashmap中采用高32位与低32位相与获得hash值
long hash64 = Hashing.murmur3_128().hashObject(value, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
//采用对低32进行变更以达到随机哈希函数的效果
for (int i = 1; i <= numHashFunctions; i++) {
int nextHash = hash1 + i * hash2;
if (nextHash < 0) {
nextHash = ~nextHash;
}
offset[i - 1] = nextHash % bitSize;
}
return offset;
}
/**
* 计算bit数组长度
* Math.log(2) = 0.6931471805599453;(取0.693147来用)
* (Math.log(2) * Math.log(2)) = 0.48045237;
* 假设传入n为1,000,000 , p为0.01;
* Math.log(0.01) = -4.605170185988091;
* 则返回值为9,585,071 ,即差不多是预设容量的10倍
*
* 要知道 1MB = 1024KB , 1KB = 1024B ,1B=8bit。
* 也就是对一百万数据预计花费的内存为1.143MB的内存
*/
private int optimalNumOfBits(long n, double p) {
if (p == 0) {
// 设定最小期望长度
p = Double.MIN_VALUE;
}
return (int) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
/**
* 计算hash方法执行次数
*/
private int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
}
【2】构建Redis实现布隆过滤器的服务类
public class BloomRedisService {
private RedisTemplate<String, Object> redisTemplate;
private BloomFilterHelper bloomFilterHelper;
public void setBloomFilterHelper(BloomFilterHelper bloomFilterHelper) {
this.bloomFilterHelper = bloomFilterHelper;
}
public void setRedisTemplate(RedisTemplate<String, Object> redisTemplate) {
this.redisTemplate = redisTemplate;
}
/**
* 根据给定的布隆过滤器添加值
*/
public <T> void addByBloomFilter(String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
redisTemplate.opsForValue().setBit(key, i, true);
}
}
/**
* 根据给定的布隆过滤器判断值是否存在
*/
public <T> boolean includeByBloomFilter(String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
if (!redisTemplate.opsForValue().getBit(key, i)) {
return false;
}
}
return true;
}
}
【3】编辑配置类
@Slf4j
@Configuration
public class BloomFilterConfig implements InitializingBean{
@Autowired
private PmsProductService productService;
@Autowired
private RedisTemplate template;
@Bean
public BloomFilterHelper<String> initBloomFilterHelper() {
return new BloomFilterHelper<>((Funnel<String>) (from, into) -> into.putString(from, Charsets.UTF_8)
.putString(from, Charsets.UTF_8), 1000000, 0.01);
}
// 布隆过滤器bean注入
@Bean
public BloomRedisService bloomRedisService(){
BloomRedisService bloomRedisService = new BloomRedisService();
bloomRedisService.setBloomFilterHelper(initBloomFilterHelper());
bloomRedisService.setRedisTemplate(template);
return bloomRedisService;
}
@Override
public void afterPropertiesSet() throws Exception {
List<Long> list = productService.getAllProductId();
log.info("加载产品到布隆过滤器当中,size:{}",list.size());
if(!CollectionUtils.isEmpty(list)){
list.stream().forEach(item->{
//LocalBloomFilter.put(item);
bloomRedisService().addByBloomFilter(RedisKeyPrefixConst.PRODUCT_REDIS_BLOOM_FILTER,item+"");
});
}
}
}
【4】构建布隆过滤器的拦截器
//拦截器,所有需要查看商品详情的请求必须先过布隆过滤器
@Slf4j
public class BloomFilterInterceptor implements HandlerInterceptor {
@Autowired
private BloomRedisService bloomRedisService;
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String currentUrl = request.getRequestURI();
PathMatcher matcher = new AntPathMatcher();
//解析出pathvariable
Map<String, String> pathVariable = matcher.extractUriTemplateVariables("/pms/productInfo/{id}", currentUrl);
//布隆过滤器存储在redis中
if(bloomRedisService.includeByBloomFilter(RedisKeyPrefixConst.PRODUCT_REDIS_BLOOM_FILTER,pathVariable.get("id"))){
return true;
}
/*
* 不在布隆过滤器当中,直接返回验证失败
* 设置响应头
*/
response.setHeader("Content-Type","application/json");
response.setCharacterEncoding("UTF-8");
String result = new ObjectMapper().writeValueAsString(CommonResult.validateFailed("产品不存在!"));
response.getWriter().print(result);
return false;
}
}
【5】将拦截器注册进SpringMVC中
@Configuration
public class IntercepterConfiguration implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
//注册拦截器
registry.addInterceptor(authInterceptorHandler())
.addPathPatterns("/pms/productInfo/**");
}
@Bean
public BloomFilterInterceptor authInterceptorHandler(){
return new BloomFilterInterceptor();
}
}
标签:
留言评论