论文信息
论文标题:Divide-and-Conquer: Post-User Interaction Network for Fake News Detection on Social Media论文作者:Erxue Min, Yu Rong, Yatao Bian, Tingyang Xu, Peilin Zhao, Junzhou Huang,Sophia Ananiadou论文来源:2022,WWW 论文地址:download 论文代码:download
Background
挑战:
(1) 谣言检测涉及众多类型的实体和关系,需要一些方法来建模异质性; (2) 社交媒体中的话题出现了分布变化,显著降低了虚假新闻的性能; (3) 现有虚假新闻数据集通常缺乏较大规模、话题多样性和用户的社交关系;
基于文本的谣言检测方法存在如下两个问题:
(1) 首先,在新闻的社会背景下的信息是复杂的和异构的;
(2) 其次是分布偏移问题——训练分布不同于测试分布;
分布偏移例子:如虚假新闻分类器是在 包含政治、体育、娱乐等普通主题的标记数据进行训练的,但是在测试集上出现了出现了诸如“黑天鹅事件”的新主题。
贡献:
We construct and publicize a new fake news dataset with social context named MC-Fake2 , which contains 27,155 news events in 5 topics, and their social context composed of 5 million posts, 2 million users and induced social graph with 0.2 billion edges.
We propose a novel Post-User Interaction Network (PSIN), which applies divide-and-conquer strategy to model the heterogeneous relations. Specifically, we integrate the post-post, user-user and post-user subgraphs with three variants of Graph Attention Networks based on their intrinsic characteristics. Additionally, we employ an additionally adversarial topic discriminator to learn topic-agnostic features for veracity classification.
We evaluate our proposed model on the curated dataset in two settings: in-topic split and out-of-topic split. The superior results of our model in both settings reveal the effectiveness of the proposed method.
2 Related work
2.1 Fake News Datasets
BuzzFeedNews specializes in political news published on Facebook during the 2016 U.S. Presidential Election.
LIAR collects 12.8K short statements with manual labels from the political fact-checking website.
FA-KES consists of 804 articles around Syrian war.
CREDBANK contains about 1000 news events and 60 million tweets, labeled by Amazon mechanical Turk.
Twitter15 contains 778 reported events between March 2015 to December 2015, with 1 million posts from 500k users.
FakeNewsNet is a data repository with news content and related posts, containing political news and entertainment news which are checked by politifact and gossiocop.
FakeHealth is collected from healthcare information review website Health News Review, it contains over 2000 news articles, 500k posts and 27k user profiles, along with user networks.
COAID collects 1,896 news, 183,654 related user engagements, 516 social platform posts about COVID-19, and ground truth labels.
FakeCovid is a multilingual cross-domain dataset of 5,182 fact-checked news article for COVID-19 from 92 different fact-checking websites.
MM-COVID is a multilingual and multidimensional COVID-19 fake news data repository, containing 3,981 pieces of fake news content and 7,192 trustworthy information from 6 different languages.
2.2 Social Context-based Fake News Detection
划分为三类:
Sequential Modeling [20, 24, 30, 52]
Explicit responding path modeling [4, 19, 26, 47]
Implicit attention modeling
3 Problem statement
假新闻数据集定义:$\mathbf{D}=\left\{\mathbf{T}, G^{U}, G^{U P}\right\}$
News event 定义:$T_{i}=\left\{p_{1}^{i}, p_{2}^{i}, \ldots p_{M_{i}}^{i}, G_{i}^{P}, u_{1}^{i}, u_{2}^{i}, \ldots u_{N_{i}}^{i}, G_{i}^{U}, G_{i}^{U P}\right\}$
News event can be considered as a heterogeneous graph two types of nodes: post and user, and three types of edges: post-post, user-user and user-post.as shown in Figure 2:
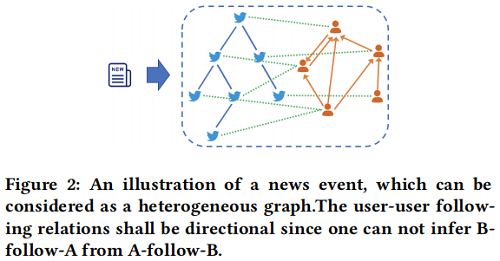
在本文的数据集中,每一个 $T_i$ 均有一个主题标签 $y_{i}^{C} \in\{ Politics, Entertainment, Health, Covid-19, Sryia War\}$ 和 groundtruth veracity label $y_{i}^{V} \in\{F, R\}$ (i.e. Fake, news or Real news)。
4 Methodlogy
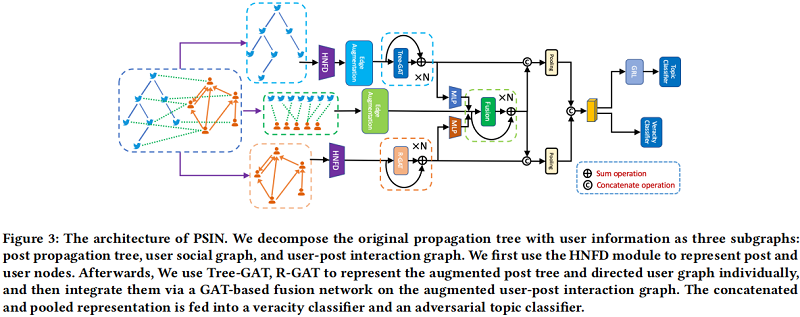
4.1 Hybrid Node Feature Encoder
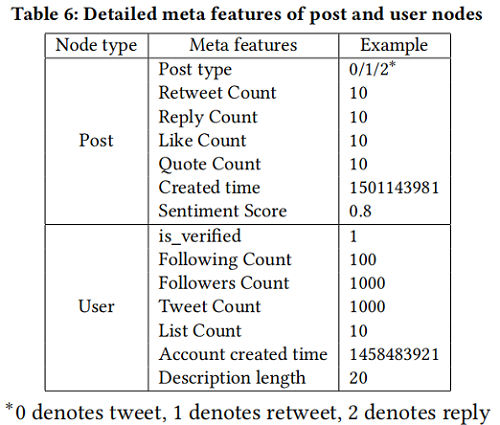
对于 event $i$ $T_{i}$,节点集合 $\left\{p_{1}^{i}, p_{2}^{i}, \ldots p_{M_{i}}^{i}, u_{1}^{i}, u_{2}^{i}, \ldots u_{N_{i}}^{i}\right\}$,每个节点拥有 textual features 和 meta features。Post 和 user 的 meta feature 如下:
4.1.1 Text Content Encoding
常用的文本编码方式:TF-IDF、CNN、LSTM、Transformer、BERT。
本文的文本词向量通过 CNN 获得,设 $c_j$ 为第 $j$ 个节点提取的文本嵌入。
4.1.2 Meta feature based Gate Mechanism
文本嵌入压缩了重要的语义信息,然而,每个节点的重要性是不同的。直观地说,转发数或关注者数等元特征(meta feature)意味着受欢迎程度和社会关注,这可用来推断给定节点的重要性。因此,设计了一个基于元特征的门机制来过滤文本特征,如 Figure 4 所示。
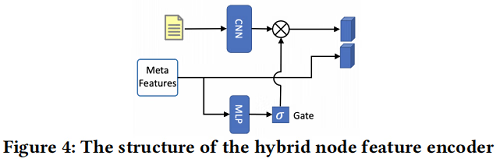
具体来说,给定第 $j$ 个节点的元特征 $m_j$,我们计算其贡献分数,以衡量第 $j$ 个节点的文本特征的重要性:
$g_{j}=\sigma\left(\mathbf{W}^{m} \mathbf{m}_{j}+\mathbf{b}^{m}\right)$
其中 $\sigma$ 是一个激活函数,它将输入映射到 $[0,1]$ 中,$\mathbf{W}^{m}$ 和 $\mathbf{b}^{m}$ 都是可训练的参数。最后,第 $j$ 个节点的表示如下:
$\mathbf{n}_{j}=g_{j} \mathbf{c}_{j} \oplus \mathbf{m}_{j}$
其中,$\oplus$ 是连接操作符。因此,给定输入序列 $\left\{p_{1}, p_{2}, \ldots p_{M}, u_{1}, u_{2}, \ldots u_{N}\right\}$ 对于第 $i$ 个新闻事件,我们得到帖子特征矩阵 $\mathbf{P}=\left\{\mathbf{h}_{1}^{P}, \mathbf{h}_{2}^{P}, \ldots, \mathbf{h}_{M}^{P}\right\}$ 和用户特征矩阵 $\mathbf{U}=\left\{\mathbf{h}_{1}^{U}, \mathbf{h}_{2}^{U}, \ldots \mathbf{h}_{N}^{U}\right\}$。
4.2 Post Tree Modeling

采用图结构建模的原因:
1:帖子深层之后任然存在联系,尤其是对于源推文极具争议性的时候;
2:回复贴对于源帖的密切回复;
本文提出的图结构信息建模的方法是:Tree-GAT ,包括两个模块:
Edge Augmentation
Depth-aware Graph Attention
设 $A^{P}$ 为第 $i$ 个新闻事件的传播树 $G^{P}$ 的邻接矩阵,$A_{i j}^{P}=1$ 表示第 $i$ 个帖子回应了第 $j$ 个帖子。我们计算增广邻接矩阵 $\widehat{A}^{P}$ 如下:
$\begin{array}{l}A_{\mathrm{BU}}^{P}=\sum\limits_{d=1}^{d_{\max }}\left(A^{P}\right)^{d}\\A_{\mathrm{TD}}^{P}=A_{B U}^{P}{ }^{\top} \\\widehat{A}^{P}=A_{B U}^{P}+A_{T D}^{P}\end{array}$
其中,$d_{max}$ 为新闻事件中传播树的最大深度。
Depth-aware Graph Attention
给定增强的邻接矩阵 $\widehat{A}^{P}$ 和帖子特征矩阵 $\mathbf{H}^{0}=\left\{\mathbf{h}_{1}^{0}, \mathbf{h}_{2}^{0}, \ldots, \mathbf{h}_{M}^{0}\right\}$,本文使用 GATv2 作为 backbone
$e_{i j}=\mathbf{a}^{\top} \operatorname{Leaky} \operatorname{ReLU}\left(\mathbf{W} \cdot\left[\mathbf{h}_{i} \| \mathbf{h}_{j}\right]\right) $
${\large \alpha_{i j}=\operatorname{Softmax}\left(e_{i j}\right)=\frac{\exp \left(e_{i j}\right)}{\sum\limits _{k \in \mathcal{N}(i)} \exp \left(e_{i k}\right)}} $
$\mathbf{a} \in \mathbb{R}^{d}$ is a parameter vector
$\mathbf{W}=\left[\mathbf{W}_{s} \| \mathbf{W}_{d}\right]$ with $\mathbf{W}_{s}$ and $\mathbf{W}_{d}$ are parameter matrices to project source nodes and target nodes
$e_{i j}$ and $\alpha_{i j}$ are unnormalized and normalized attention
远程节点中存在语义漂移,故对注意力进行修改:
$e_{i j}=\mathbf{a}^{\top} \operatorname{LeakyReLU}\left(\mathbf{W} \cdot\left[\mathbf{h}_{i} \| \mathbf{h}_{j}\right]+\mathbf{v}[d(i, j)]\right)$
其中,$d(i, j)=d_{i}-d_{j}+d_{\max }$ ,$d_{i}$ 为第 $i$ 个节点的深度,$d_{max}$ 为所有树的最大深度,$\mathbf{v}[d(i, j)] \in \mathbb{R}^{d}$ 是可训练的位置向量,使网络能够感知节点之间的相对位置(相对时间顺序和相对深度)。此外,还在更新方程中添加了残差连接:
${\large \mathbf{h}_{i}^{\prime}=\sigma\left(\sum\limits_{j \in \mathcal{N}(i)} \alpha_{i j} \mathbf{W}_{d} \mathbf{h}_{j}\right)+\mathbf{h}_{i}} $
假设 $\mathbf{H}^{0}=\mathbf{P}$ ,经过 $K$ 层 Tree-GAT ,有 $\widehat{\mathbf{P}}=\mathbf{H}^{K}=\left\{\widehat{\mathbf{h}}_{1}^{P}, \widehat{\mathbf{h}}_{2}^{P}, \ldots, \widehat{\mathbf{h}}_{M}^{P}\right\}$ 。
$\begin{array}{l}\mathrm{A}^{\text {friend }}&=&\mathrm{A}^{U} \cdot \mathrm{A}^{U^{\top}}\\\mathrm{A}^{\text {follow }} &=&\mathrm{A}^{U}-\mathrm{A}^{\text {friend }} \\\mathrm{A}^{\text {followed }} &=&\mathrm{A}^{U^{\top}}-\mathrm{A}^{\text {friend }}\end{array}$
为了区分消息传递过程中的不同边,我们提出了 Relational Graph Attention Network(R-GAT),该方法计算节点之间的注意得分如下:
$e_{i j}=\mathbf{a}_{r(i, j)}^{\top} \operatorname{LeakyReLU}\left(\mathbf{W} \cdot\left[\mathbf{h}_{i} \| \mathbf{h}_{j}\right]\right)$
其中,
$r(i, j) \in\{0,1,2\}$ 代表三种边的关系,$\mathbf{a}_{0}, \mathbf{a}_{1}, \mathbf{a}_{2}= a_{0}+a_{1}$ 是三个不同向量参数分别代表了 follow relations,followed relations 和 friend relations。
和 post 节点类似进行标准化和更新步骤(带残差)。
4.4 Post-User Interaction
用户和帖子之间的交互也为准确性检测提供了线索。例如,有一些异常的账户可能会在一个新闻事件中发布数百条帖子。这些账户可以是出于某些目的而旨在传播信息的机器人,也可以是希望中断传播过程的事实核查账户。后传播树建模和用户网络建模都不能捕获这样的模式。为此,我们提出了一个 user-post fusion layer 来丰富用户节点和帖子节点的表示。
我们根据用户的行为构建了一个用户发布图。如 Figure 6 所示,我们假设给定帖子的传播者可以表达其产生的社会效应模式,而用户传播的帖子描述了用户的特征。基于此假设,我们计算了 bipartite user-post graph 的邻接矩阵 $\widehat{\mathrm{A}}^{U P} \in \mathbb{R}^{N \times M}$ 为:
$\widehat{\mathrm{A}}^{U P}=\mathrm{A}^{U P}\left(\sum_{d=1}^{d_{\max }}\left(\mathrm{A}^{P}\right)^{d}\right)$
其中,$\mathrm{A}^{U P} \in \mathbb{R}^{N \times M}$ 为 is-author graph $G^{UP}$ 的邻接矩阵,$\mathrm{A}^{P}$ 是上述增强图的邻接矩阵。为了在 user-post graph 中使用 GNN,我们首先使用两个投影矩阵将它们的表示投影到一个统一的空间中:
$\mathbf{H}^{P}=\mathbf{W}^{P} \widehat{\mathbf{P}}, \mathbf{H}^{U}=\mathbf{W}^{U} \widehat{\mathbf{U}}$
然后,我们将该图视为齐次图,得到 $\mathbf{H}= Concat \left(\mathrm{H}^{P}, \mathrm{H}^{U}\right)$。邻接矩阵的定义为:
$\tilde{A}=\left[\begin{array}{cc}\mathrm{A}^{U P^{T}} & 0 \\0 & \mathrm{~A}^{U P}\end{array}\right]$
我们使用标准的 GATv2 来表示节点,每个层的更新规则是:
$\mathrm{H}^{\prime}=\mathrm{GATv} 2(\mathrm{H}, \widetilde{\mathrm{A}})+\mathrm{H} \text {. }$
我们在 post-user interaction layers 之后得到 $\widetilde{\mathbf{H}}=\left\{\widetilde{\mathbf{h}}_{1}^{P}, \widetilde{\mathbf{h}}_{2}^{P}, \ldots, \widetilde{\mathbf{h}}_{M}^{P}, \widetilde{\mathbf{h}}_{1}^{U}, \widetilde{\mathbf{h}}_{2}^{U}, \ldots, \widetilde{\mathbf{h}}_{N}^{U}\right\}$ 。然后我们获得帖子和用户的最终表示为 $\mathbf{P}^{\prime}=\left\{\mathbf{h}_{1}^{P^{\prime}}, \mathbf{h}_{2}^{P^{\prime}}, \ldots, \mathbf{h}_{M}^{P^{\prime}}\right\}$,$\mathbf{U}^{\prime}=\left\{\mathbf{h}_{1}^{U^{\prime}}, \mathbf{h}_{2}^{U^{\prime}}, \ldots, \mathbf{h}_{N}^{U^{\prime}}\right\}$,其中,$\mathbf{h}_{i}^{P^{\prime}}=\operatorname{Concat}\left(\widehat{\mathbf{h}}_{i}^{P}, \widetilde{\mathbf{h}}_{i}^{P}\right)$ 和 $\mathbf{h}_{i}^{U^{\prime }}=\operatorname{Concat}\left(\widehat{\mathbf{h}}_{i}^{U}, \widetilde{\mathbf{h}}_{i}^{U}\right) $。
4.5 Aggregation
给定帖子和用户的表示:$\mathrm{P}^{\prime} \in \mathbb{R}^{M \times d}, \mathbf{U}^{\prime} \in \mathbb{R}^{N \times d}$,我们采用三个全局注意层将它们分别转换为两个固定大小的向量。全局注意层的表述为:
$\mathbf{r}=\sum_{k=1}^{K} \operatorname{Softmax}\left(f\left(\mathbf{h}_{k}\right)\right) \odot \mathbf{h}_{k}$
其中, $f: \mathbb{R}^{d} \rightarrow \mathbb{R}$ 是一个两层 MLP。最后,我们得到两个合并向量 $\mathbf{p}$,$\mathbf{u} $,并将它们连接起来,得到第 $i$ 个新闻事件的最终表示为 $\mathrm{z}=\operatorname{Concat}(\mathbf{p}, \mathbf{u})$。
4.6 Topic-agnostic Fake News Classification
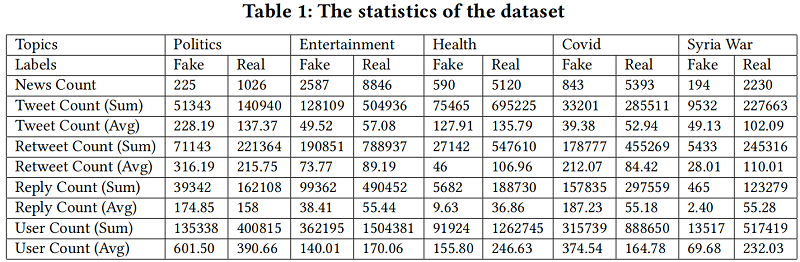
如 Table 1 所示,不同主题之间的传播特征差异很大,我们提出了一个辅助 adversarial module 和 a veracity classifier 来学习类判别和域不变节点表示。总体目标如下:
$\mathcal{L}\left(\mathrm{Z}, \mathrm{Y}^{V}, \mathrm{Y}^{C}\right)=\mathcal{L}_{V}\left(\mathrm{Z}, \mathrm{Y}^{V}\right)+\gamma \mathcal{L}_{C}\left(\mathrm{Z}, \mathrm{Y}^{C}\right)$
其中,$\gamma$ 是平衡参数。$\mathcal{L}_{V}$ 和 $\mathcal{L}_{C}$ 分别表示准确性分类器损失和主题分类器损失。$Z$ 是整个数据集提取的特征矩阵,$\mathrm{Y}^{V}$ 是准确性标签,$\mathrm{Y}^{C}$ 是主题标签。具体介绍如下:
4.6.1 Veracity Classifier Loss
准确性分类器损失 $\mathcal{L}_{V}\left(\mathrm{Z}, \mathrm{Y}^{V}\right)$ 是为了最小化准确性分类的交叉熵损失:
$\mathcal{L}_{V}\left(\mathrm{Z}, \mathrm{Y}^{V}\right)=-\frac{1}{N_{t}} \sum_{i=1}^{N_{t}} y_{i}^{V} \log \left(f_{V}\left(\mathbf{z}_{i}\right)\right)$
其中 $f_{V}: \mathbb{R}^{d} \rightarrow \mathbb{R}$ 是一个MLP分类器,$\mathrm{z}_{i}$ 是第 $i$ 个新闻事件的特征,$y_{i}^{V} \in\{0,1\}$ 是相应的准确性标签,$N_{t}$ 是训练集中的实例数。
4.6.2 Topic Classifier Loss
主题分类器损失 $\mathcal{L}_{C}\left(\mathrm{Z}, \mathrm{Y}^{C}\right)$ 要求不同主题的特征提取过程后的表示是相似的。为了实现这一点,我们学习了一个由 $\theta_{C}$ 参数化的主题分类器 $f_{C}\left(\mathrm{Z} ; \theta_{C}\right)$ 和一个对抗性训练方案。一方面,我们希望 $f_{V}$ 能够将每个新闻事件分类为正确的准确性标签。另一方面,我们希望来自不同主题的特征相似,这样主题分类器不能区分新闻事件的主题。在我们的论文中,我们使用梯度反转层(GRL)来进行对抗性训练。数学上,GRL 被定义为 $Q_{\lambda}(x)=x$,具有反转梯度 $\frac{\partial Q_{\lambda}(x)}{\partial x}=-\lambda I$。$\theta_{C}$ 通过最小化交叉熵主题分类器的损失来进行优化:
$\mathcal{L}_{C}\left(\mathrm{Z}, \mathrm{Y}^{t}\right)=-\frac{1}{N_{t}} \sum_{i=1}^{N_{t}} y_{i}^{C} \log \left(f_{C}\left(\mathbf{z}_{i}\right)\right)$
其中,$y_{i}^{C}$ 表示第 $i$ 个新闻事件的主题标签。对 $\mathcal{L}_{V}\left(\mathrm{Z}, \mathrm{Y}^{V}\right)$ 和 $\mathcal{L}_{C}\left(\mathrm{Z}, \mathrm{Y}^{C}\right)$ 进行联合优化,并采用标准的反向传播算法对所有参数进行优化。
5 Experiments
5.1 Baselines
PPC_RNN+CNN [23]: A fake news detection approach combining RNN and CNN, which learns the fake news representations through the characteristics of users in the news propagation path.
RvNN [25]: A tree-structured recursive neural network with GRU units that learn the propagation structure.
Bi-GCN [4]: A GCN-based rumour detection model using bi-directional GCN to represent the propagation structure.
PLAN [17]: A post-level attention model that incorporates tree structure information in the Transformer network.
FANG [28]: A graphical fake news detection model based on the interaction between users, news, and sources. We remove the source network modeling part for fair evaluation.
RGCN [33]: The relational graph convolutional network keeps a distinct linear projection weight for each edge type.
HGT [13]: Heterogeneous Graph Transformer leverages nodeand edge-type dependent parameters to characterize the heterogeneous attention over each edge.
PSIN : Our proposed Post-User Interaction Model.
PSIN(-T): PSIN without the adversarial topic discriminator. We compare it with other baselines to demonstrate the superiority of our network architecture.
5.2 Settings
对于PPC_RNN+CNN、RvNN、Bi-GCN和PLAN,我们将post特征与相应的用户特征连接起来,生成节点特征,以适应它们的架构。
对于 RGCN 和 HGT,我们将 post 和用户视为两组节点,这与 PSIN 是相同的。
我们在两种设置下评估这些方法:主题内分割和主题外分割。
在主题内分割设置中,我们将数据集分成训练集、验证集和测试集,比例为 6:2:2,进行了三次分割以追求稳定结果。
在主题外分割设置中,我们根据 Table 2 所示的主题分割数据集,我们将数据分割为训练和验证集,比例为 8:2,以构建训练集和验证集。
由于数据集中的标签是不平衡的,我们采用广泛使用的 AUC 和 F1 评分作为评价的评价度量。
我们将每个事件的帖子数限制在 2000 个,优化器选择 Adam,学习速率从 $\left\{10^{-3}, 10^{-4}, 10^{-5}\right\}$ 中选择。
batch_size 设置为 $32$,词向量维度和网络 hidden size 大小设置为 $100$ ,dropout 从 $0.1$ 到 $0.9$ 之间选择,每个部分的神经网络层数从 $\{2,3,4\}$ 中选择, $\gamma$ 从 $\{0.01,0.1,0.5,1.0\}$ 中选择, $\lambda$ 从 $\{0.01,0.1,1.0\}$ 中选择。
5.3 Overall Performance
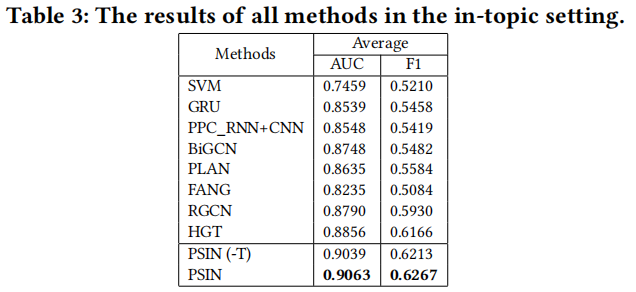
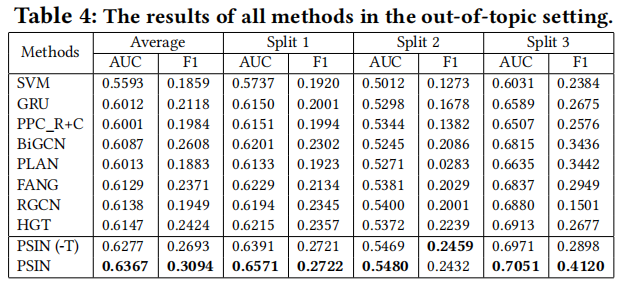
这里 FANG 是利用了 user 和 post 交互信息的图模型(公平起见去掉了原网站信息),FANG 在域内的结果次于 Bi-GCN 和 PLAN(没有有效利用 post 内容和结构),但是在跨域分类结果相反,这代表 post-tree 方法更可能过拟合,从而削弱其对新主题事件的泛化能力。
PSIN 在这两种设置下都优于 PSIN(-T),而且在跨域设置中差距更显著,这表明对抗性主题分类器减轻了过拟合问题,并使模型学习泛化性更强的特征来准确性检测。
5.4 Ablation Study

(-G) 没有文本特征提取器的门控机制, (-G) denotes our model with the gated mechanism for text feature extractor.(?without?)
(-A) post网络和post-user网络中都没有边缘增强技术的模型。
(-C) 没有post-user交互网络。
(-T) 表示没有对抗性的主题分类器。在跨域作用明显
5.5 Early Detection

5.6 Visualization of Effects of the Adversarial Topic Discriminator
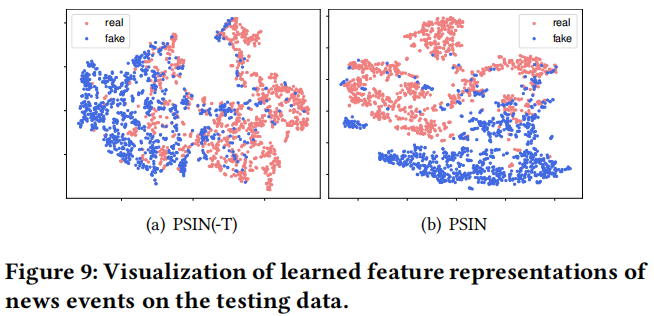
为了进一步分析对抗性主题鉴别器的有效性,我们将PSIN特征提取器学习到的最终特征用tSNE定性可视化 如图所示。
标签: # 谣言检测
留言评论