从 CPU 时间说起...
下面这个是 top 命令的界面,相信大家应该都不陌生。
top - 19:01:38 up 91 days, 23:06, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 151 total, 1 running, 149 sleeping, 1 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.1 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8010420 total, 5803596 free, 341300 used, 1865524 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 6954384 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
13436 root 20 0 1382776 28040 5728 S 0.3 0.4 251:21.06 n9e-collector
1 root 20 0 43184 3384 2212 S 0.0 0.0 5:15.64 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.28 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.58 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
7 root rt 0 0 0 0 S 0.0 0.0 0:35.48 migration/0
%Cpu(s): 这一行表示的是 CPU 不同时间的占比,其中大家比较熟悉的应该是 system time 与 user time:
- 正常情况下
user time占比应该最高,这是进程运行应用代码的的时间占比(CPU 密集) - 而
system time占用率高,则意味着存在频繁的系统调用(IO 密集)或者一些潜在的性能问题
不熟悉的朋友可以参考下面这张图(来源于极客时间的课程):

接下来我们将探究隐藏在这些时间背后的操作原理。
内核态与用户态
操作系统的核心功能就是管理硬件资源,因此不可避免会使用到一些直接操作硬件的CPU指令,这类指令我们称之为特权指令。特权指令如果使用不当,将会导致整个系统的崩溃,因此操作系统提供了一组特殊的资源访问代码 —— 内核kernel 来负责执行这些指令。
操作系统将虚拟地址空间划分为两部分:
- 内核空间
kernel memotry:存放内核代码和数据(进程间共享) - 用户空间
user memotry:存放用户程序的代码和数据(相互隔离)
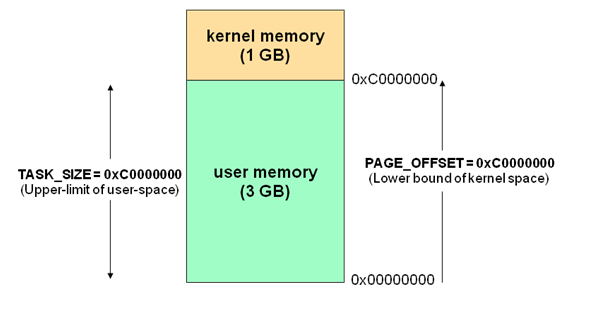
通过区分内核空间和用户空间的设计,隔离了操作系统代码与应用程序代码。即便是单个应用程序出现错误也不会影响到操作系统的稳定性,这样其它的程序还可以正常的运行。
应用程序通过内核提供的接口,访问 CPU、内存、I/O 等硬件资源,我们将该过程称为系统调用system call。系统调用是操作系统的最小功能单位。
每个进程处于活动状态时,可能处于以下两种状态之一:
- 执行用户空间的代码时,处于用户态
- 执行内核空间的代码时(系统调用),处于内核态
每次执行系统调用时,都需要经历以下变化:
- CPU 保存用户态指令,切换为内核态
- 在内核态下访问系统资源
- CPU 恢复用户态指令,切换回用户态
而之前的 user time 与 system time 分别就是对应 CPU 在用户态与内核态的运行时间。
上下文切换
当发生以下状况时,线程会被挂起,并由系统调度其他线程运行:
- 等待系统资源分配
- 调用
sleep主动挂起 - 被优先级更高的线程抢占
- 发生硬件中断,跳转执行内核的中断服务程序
同个进程下的线程共享进程的用户态空间,因此当同个进程的线程发生切换时,都需要经历以下变化:
- CPU 保存线程 A 用户态指令,切换为内核态
- 保存线程 A 私有资源(栈、寄存器...)/li>
- 加载线程 B 私有资源(栈、寄存器...)
- CPU 恢复线程 B 用户态指令,切换回用户态
不同线程的用户态空间资源是相互隔离的,当不同进程的线程发生切换时,都需要经历以下变化:
- CPU 保存线程 A 用户态指令,切换为内核态
- 保存线程 A 私有资源(栈、寄存器...)
- 保存线程 A 用户态资源(虚拟内存、全局变量...)
- 加载线程 B 用户态资源(虚拟内存、全局变量...)
- 加载线程 B 私有资源(栈、寄存器...)
- CPU 恢复线程 B 用户态指令,切换回用户态
每次保存和恢复上下文的过程,都是在系统态进行的,并且需要几十纳秒到数微秒的 CPU 时间。当切换次数较多时会耗费大量的 system time,进而大大缩短了真正运行进程的 user time。
当用户线程过多时,会引起大量的上下文切换,导致不必要的性能开销。
线程调度
Linux 中的线程是从父进程 fork 出的轻量进程,它们共享父进程的内存空间。
Linux 的调度策略是抢占式的,每个线程都有优先级prirority的概念,并按照优先级高低分为两种:
- 实时进程(优先级 0~99)
- 普通进程(优先级 100~139)
每个 CPU 都有自己的运行队列 runqueue,需要运行的线程会被加入到这个队列中。
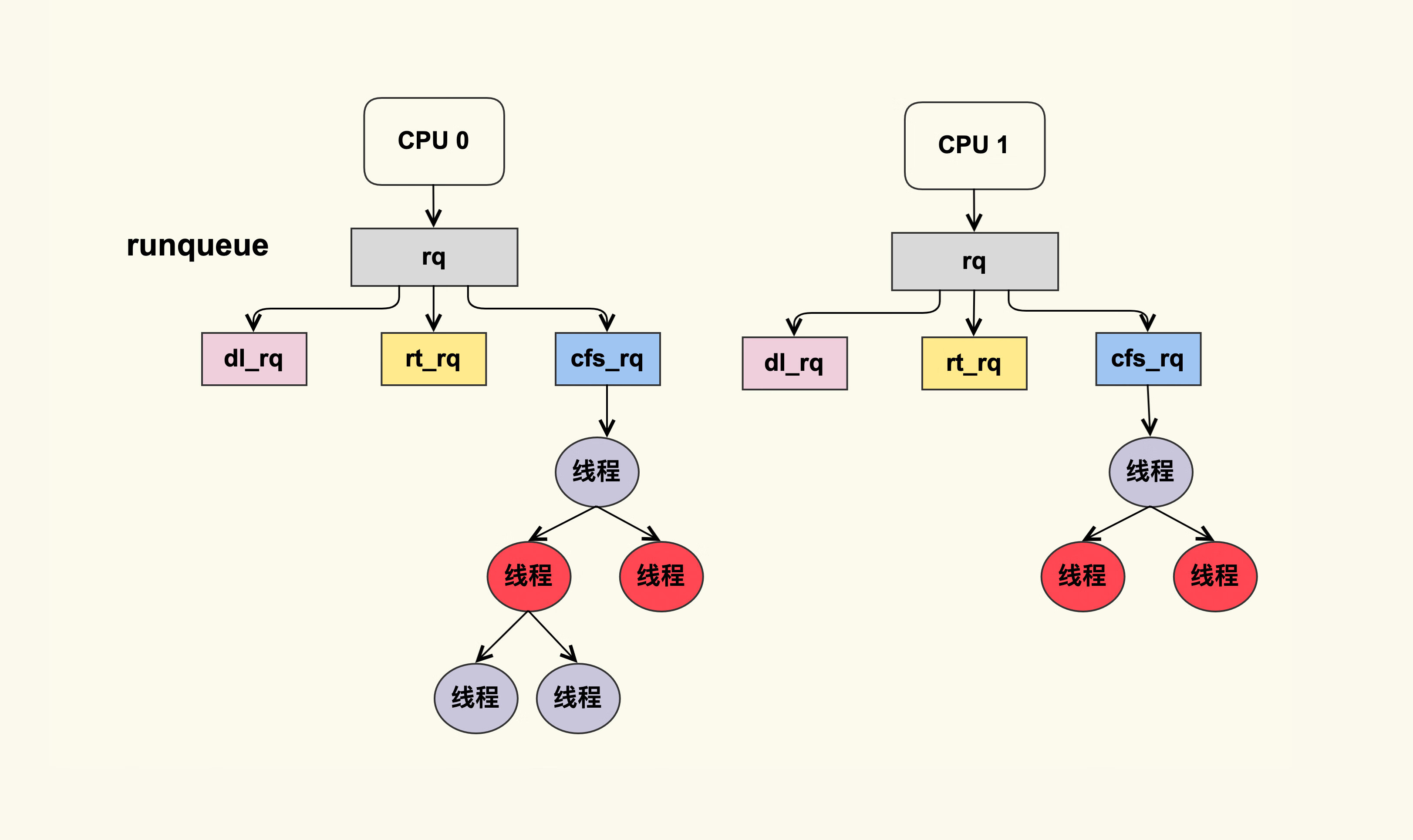
每个队列可以进一步细分为 3 个队列以及 5 种调度策略:
dl_rqSCHED_DEADLINE选择deadline距离当前时间点最近的任务执行
rt_rq—— 可以互相抢占的实时任务SCHED_FIFO一旦抢占到 CPU 资源,就会一直运行直到退出,除非被高优先级抢占SCHED_RR当 CPU 时间片用完,内核会把它放到队列末尾,可以被高优先级抢占
cfs_rq—— 公平占用 CPU 时间的普通任务SCHED_NORMAL普通进程SCHED_BATCH后台进程
Linux 内核在选择下一个任务执行时,会按照该顺序来进行选择,也就是先从 dl_rq 里选择任务,然后从 rt_rq 里选择任务,最后从 cfs_rq 里选择任务。所以实时任务总是会比普通任务先得到执行。
实时进程的优先级总是高于普通进程,因此当系统中有实时进程运行时,普通进程几乎是无法分到时间片的。
nice 值
为了保证 cfs_rq 队列的公平性,Linux 采用完全公平调度算法 CFS Completely Fair Scheduler进行调度,保证每个普通进程都尽可能被调度到。
CFS 引入了 vruntime 作为衡量是否公平的依据:
vruntime与任务占用的 CPU 时间成正比vruntime与任务优先级成反比(优先级越高vruntime增长越慢)
如果一个任务的 vruntime 较小,说明它以前占用 CPU 的时间较短,受到了不公平对待,因此该进程会被优先调度,从而到达所谓的公平性。
为了实现可控的调度,Linux 为普通进程引入了 nice 值的概念。其的取值其范围是 -20 ~ +19,调整该值会改变进程的优先级:prirority += nice。
与此同时 vruntime 计算也会受到影响:
当用户进程设置了一个大于 0 的 nice 值时,其用户态的运行时间将被统计为nice time 而不是 user time。简单来说,nice time 表示 CPU 花了多少时间用于运行低优先级的任务。
当 nice time 占比比较高时,通常是某些定时任务调度器导致的:它们会为后台任务进程设置一个较大的 nice 值,避免这些进程与其他线程争抢 CPU 资源。
软中断
中断就是一种插队机制,可以让操作系统优先处理一些紧急的任务。当硬件设备(例如,网卡)需要向 CPU 发出信号时(例如,数据已到达),就会产生硬件中断。
CPU 接收到中断时,会切换到内核态执行特定的中断服务,并且期间不允许其他中断抢占(关中断)。 当中断服务需要执行较长时间时,可能会导致且其他的中断得不到及时的响应。
为了提高中断处理效率,操作系统在之前的基础上把中断处理分成两部分:
- 上半部
top half:在屏蔽中断的上下文中运行,用于完成关键性的处理动作 - 下半部
bottom half:不在中断服务上下文中执行,主要处理不那么急迫但耗时的任务
内核在处理完中断上半部后,可以延期执行下半部,该机制被称为软中断softirq。
软中断处理的过程是不会关中断的,因此当有硬中断到来的时候,可以及时响应。
构成软中断机制的核心元素包括:
- 注册: 软中断状态寄存器
irq_stat - 处理: 软中断向量表
softirq_vec - 触发: 软中断守护线程
daemon
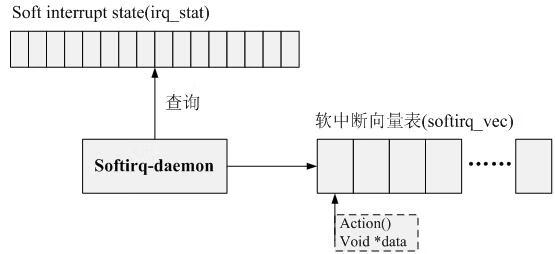
调用
open_softirq()将软中断服务程序注册到软中断向量表softirq_vec(可选)调用
raise_softirq()触发软中断事务- 中断关闭的情况下,设置软中断状态位
irq_stat - 如果调用者不在中断上下文(普通进程调用),那么直接唤醒
daemon线程
- 中断关闭的情况下,设置软中断状态位
daemon线程被唤醒后会运行do_softirq()处理软中断- 检查
irq_stat是否存发生软中断事件 - 调用
softirq_vec中对应的软中断服务程序 - 再次检查
irq_stat,如果发现新的软中断,就会唤醒ksoftrqd线程来处理
- 检查
ksoftrqd 机制
我们知道 CPU 执行的优先级为:硬中断 > 软中断 > 普通进程。 这意味着:
- 一个软中断不会去抢占另一个软中断,只有硬件中断才可以抢占软中断
- 如果软中断太过频繁,用户进程可能永远无法获得 CPU 时间
为了保证公平性,内核为每个 CPU 都配置一个ksoftrqd线程。如果所有的软中断在短时间内无法被处理完,内核就会唤醒ksoftrqd处理剩余的软中断。以下面这张图为例:
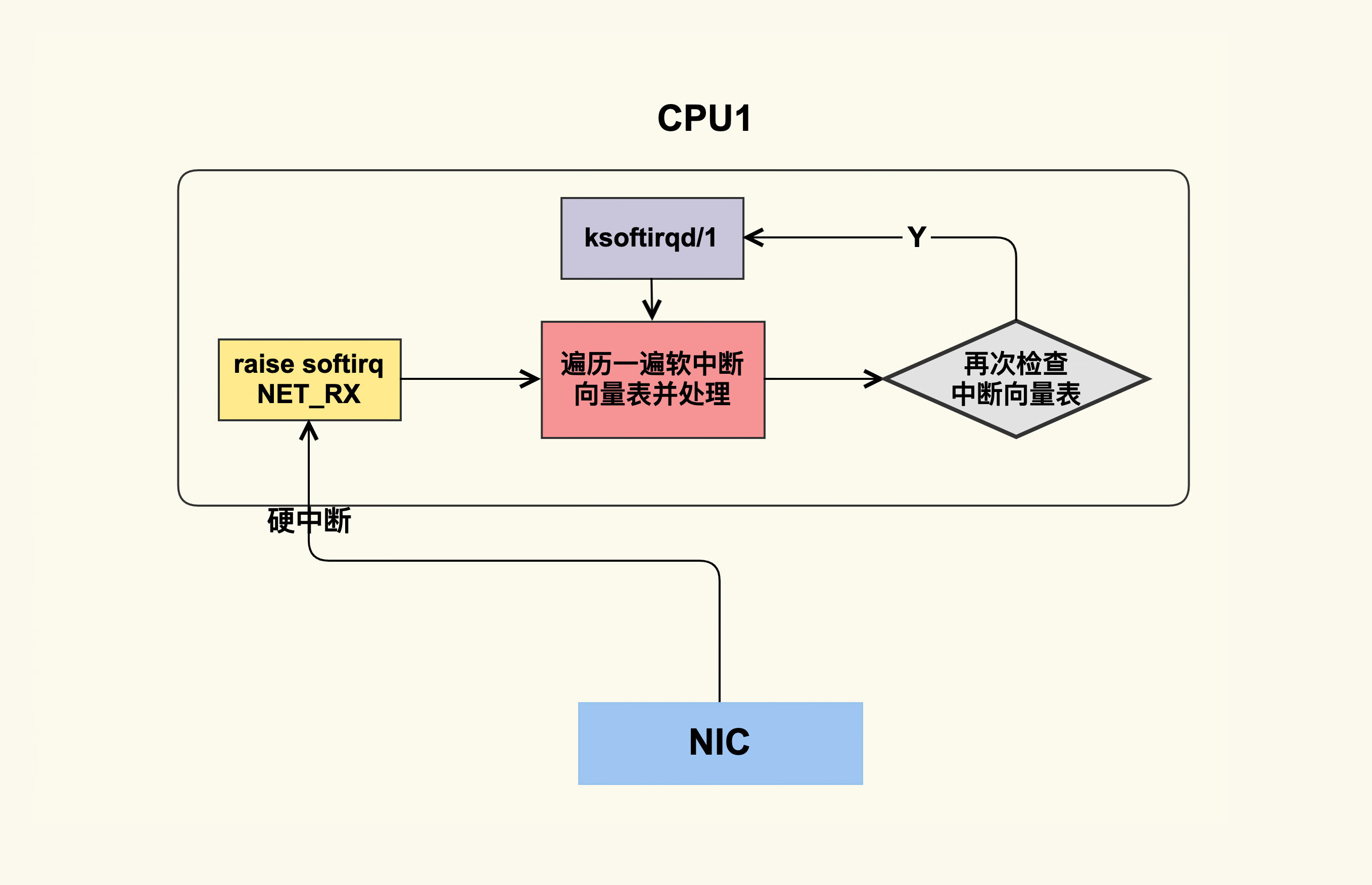
- 网卡数据就绪,通过硬中断通知 CPU 进行处理
- 硬中断服务程序调用
raise_softirq()触发软中断,唤醒daemon - 硬中断服务程序退出后,
daemon被唤醒开始处理软中断 - 遍历过一遍向量表后,
daemon发现仍有未处理的软中断,唤醒ksoftrqd ksoftrqd获得 CPU 时间片后,继续处理未完成的软中断
由于 ksoftrqd 其实是一个 nice 值为 0 的普通线程,会进入 cfs_rq 参与调度,可以和普通进程公平地使用 CPU。
但如果 ksoftrirqd 长时间得不到 CPU,就会致使软中断的延迟变得很大,因此 ksoftirqd 的实时性是很难得到保障。
典型问题是 ping 延迟:如果 ping 包无法在软中断里得到处理,就会被 ksoftirqd 处理,导致 ping 延迟变得很大。
中断的影响
硬中断的优先级很高,但是需要的 CPU 时间极少。当出现大量硬中断时,可能会引起较多的 CPU 用户态与内核态的切换,但是interrupt time不会显著上升。
此外,由于部分内核代码是不可重入的(例如,修改寄存器),其执行过程不能打断。因此这些代码的执行过程中,会屏蔽掉硬中断。
关中断的操作在内核里随处可见,这反过来会给硬中断带来一些影响。比如,进程关中断时间太长会导致网络报文无法及时处理,进而引起业务性能抖动。
而软中断的执行时间如果太长,就会给用户线程带来延迟,如果 softirq time 很大则很可能意味着用户线程会受到影响。
网络 IO 频繁的应用机器的 softirq time 通常会比较高,可能存在网络连接数过多,或者网络流量过大的情况,
ksoftirqd 的优先级与用户线程是一致的,因此,如果软中断处理函数是在 ksoftirqd 里执行的,那它可能会有一些延迟。
时间窃取
在 GNU top命令中,steal time定义为 “虚拟机管理进程 hypervisor 从 VM 窃取的时间”。 该概念是Xen,KVM,VMware 等社区或者厂商推广到Linux社区的。
当系统管理进程和 VM 尝试占用同一物理 CPU 核 pCPU 时,会导致 VM 的虚拟 CPU vCPU 可用的处理器时间减少,从而造成 VM 性能下降。
中虚拟化环境中,可能发生时间窃取的一些情况:
- 多个高负载 VM 的
vCPU的运行在同个pCPU上(公有云的 CPU 超卖) - VM 的
vCPU与线程绑定在了某个特定的pCPU上,导致虚拟主机vhost进程处理 I/O 时从这些vCPU上窃取时间 - 虚拟机监控程序进程(例如监视,日志记录和I/O进程)与 VM 争抢
pCPU
参考资料
https://www.cnblogs.com/Anker/p/3269106.html https://zhuanlan.zhihu.com/p/69554144 https://blog.csdn.net/helloanthea/article/details/28877221 https://blog.csdn.net/lenomirei/article/details/79274073 https://www.jianshu.com/p/673c9e4817a8 https://opensource.com/article/20/1/cpu-steal-time https://www.cnblogs.com/menkeyi/p/6732020.html https://blog.csdn.net/zxh2075/article/details/78262568 https://kb.cnblogs.com/page/207897/ https://www.cnblogs.com/charlesblc/p/6255806.html http://www.wowotech.net/linux_kenrel/soft-irq.html
标签:
留言评论