前言
Kafka 有多快呢?我们可以使用 OpenMessaging Benchmark Framework 测试框架方便地对 RocketMQ、Pulsar、Kafka、RabbitMQ 等消息系统进行对比测试,因为暂时没有测试条件(后续补上),我直接用这篇文章的测试结果(Benchmarking Kafka vs. Pulsar vs. RabbitMQ: Which is Fastest?),可以看到,在某种条件下,Kafka 写入速度比 RabbitMQ 快 15 倍,比 Pulsar 快 2 倍,在最高吞吐量下仍保持低延迟。
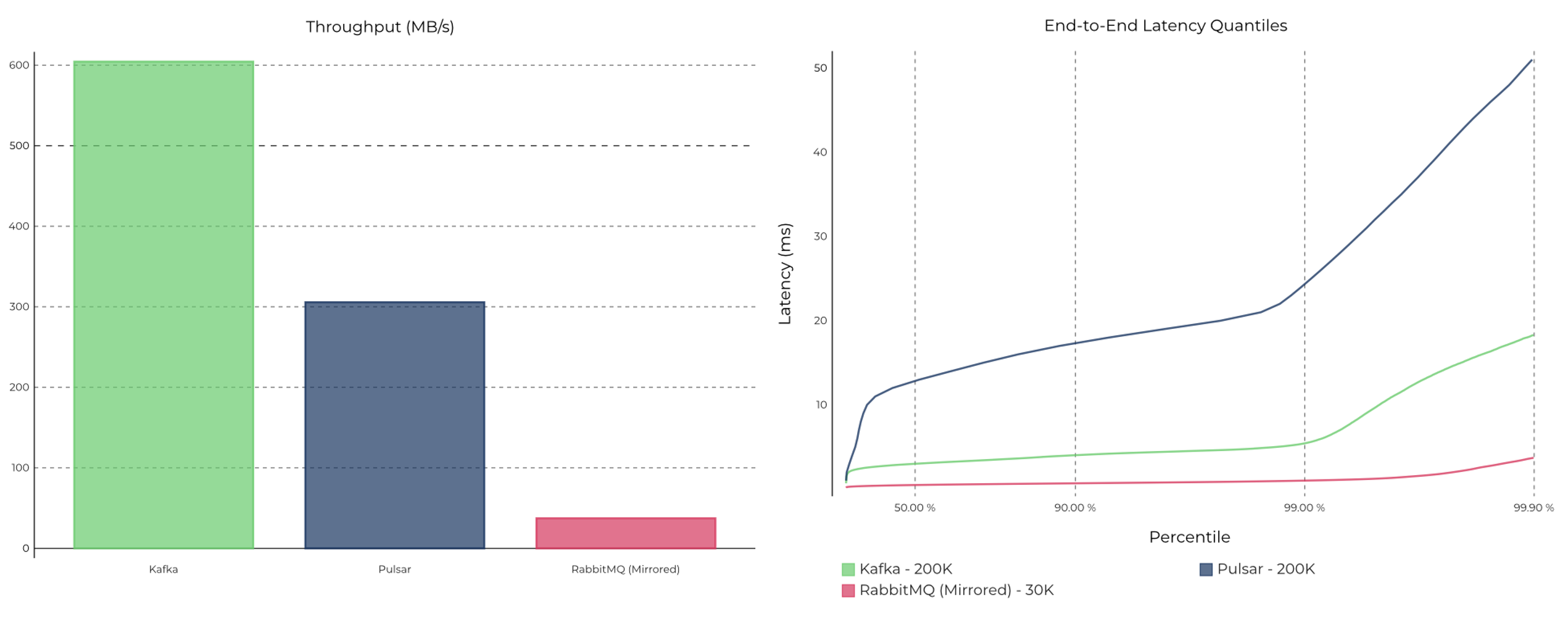
那么,为什么 Kafka 可以那么快呢?这里我先简单总结,后面会展开分析。
- 从磁盘中顺序读写 event。
- 通过批处理减少大量小 I/O。
- 从文件到 socket 之间数据零拷贝。
- 基于分区的横向扩展。
ps:[本系列](博客后台 - 博客园 (cnblogs.com))博客将持续更新。
顺序读写磁盘
Kafka 严重依赖文件系统来读写 event。我们不禁会问,磁盘不是很慢吗?Kafka 真的能提供很好的性能吗?
事实上,磁盘比人们预期的要慢得多,也快得多,这取决于它们的使用方式。在这篇文章中(ACM Queue article)可以发现,在某些情况下,顺序磁盘访问可能比随机内存访问更快。这要得益于现代操作系统对磁盘读写进行的大量的优化,包括 read-ahead 和 write-behind 技术,当我们顺序读取磁盘时,更多时候访问的不是磁盘,而是内存--pagecache。
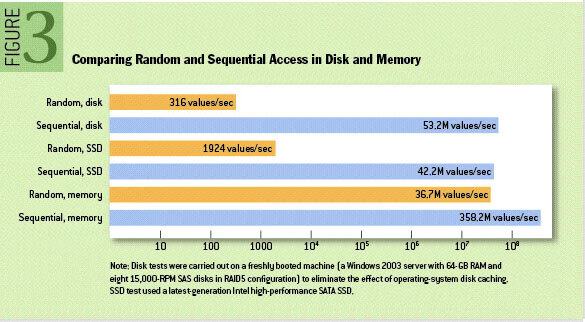
因此,只要顺序访问文件系统,磁盘也可以很快。Kafka 的 event 组织方式以及应用场景,天然地支持了顺序读写,并且 Kafka 也为此做了许多努力,例如批处理、追加写入等。
此外,相比主动将 event 维护在内存,采用文件系统还有以下好处:
可以缓存更多的数据。在 JVM 中,维护对象的内存开销将是实际数据大小的两倍甚至更糟,随着堆内数据的增加,gc 将愈发频繁。而使用文件系统可以在 pagecache 中缓存更多更紧凑的数据,而不需要考虑 gc 问题。
重启后恢复更快。由于数据缓存在 pagecache,进程重启,这部分缓存仍然可以保持 warn 的状态,如果在进程内存中维护这些数据的话,每次启动都需要重建(对于 10GB 缓存可能需要 10 分钟)。
数据不会丢失。如果数据维护在内存中,需要考虑定期将数据持久化到磁盘,一致性和性能的权衡将是一个比较麻烦的问题,即便如此,我们也不能保证数据不会丢失,例如 redis 可能损失几秒的数据,甚至更多。在理论上,Kafka 就不会出现数据丢失的情况。
大大简化了代码。用于维护缓存和文件系统之间一致性的所有逻辑现在都在操作系统中,而操作系统往往更高效、更正确。
通过批处理减少小I/O
小 I/O 操作发生在客户端和服务端之间的数据传输以及服务端自身的持久化操作。
为了避免小 I/O 操作,Kafka 是以批的形式来操作 event,而不是一次发送一条消息。producer 会尝试在内存中积累数据,并在单个请求中发送更大的批,当然,这种方式是牺牲少量额外延迟以获得更好的吞吐量,我们可以配置累积数量和等待时间来平衡。同理,consumer 读取数据时也会尝试一次读取更多。
批处理可以产生较大顺序磁盘操作和连续内存块,不过也产生了较大的网络数据包,相应地,Kafaka 会将消息压缩后发送,当消息写入日志时仍然是压缩形式,仅由使用者解压缩。
数据零拷贝
另一个问题是过多的字节复制。//zzs001
一般情况下,数据从文件传输到 socket 的数据路径为:磁盘 -》内核的 pagecache -》用户空间缓冲区 -》内核的 socket 缓冲区 -》NIC 缓冲区。

显然,这是非常低效的,有四个副本和两个系统调用。Kafka 使用 sendfile,允许操作系统将数据从 pagecache 直接发送到网络,即磁盘 -》内核的 pagecache-》NIC 缓冲区。从而避免这种重复复制和系统调用。更多关于 sendfile 的内容可以参考Efficient data transfer through zero copy。

需要注意的是,由于 TLS/SSL 库是工作在用户空间的,所以,当启用了 SSL,sendfile 将不能使用。
基于分区的横向扩展
关于这一点,在上一篇博客中其实已经提到过。首先,一个 topic 会划分成一个或多个 partition,这些 partition 一般分布在不同的 broker 实例。producer 发布的 event 会根据某种策略分配到不同的 partition,这样做的好处是,consumer 可以同时从多台 broker 读取 event,从而大大提高吞吐量。另外,为了高可用,同一个 partition 还会有多个副本,它们分布在不同的 broker 实例,和很多传统的消息系统不同,Kafka 的副本是可读的,即 consumer 不仅可以从主 partition 读取 event,也可以从副本读取。//zzs001

结语
以上内容是最近学习 Kafka 的一些思考和总结(主要参考官方文档),如有错误,欢迎指正。
任何的事物,都可以被更简单、更连贯、更系统地了解。希望我的文章能够帮到你。
最后,感谢阅读。
参考资料
Benchmarking Kafka vs. Pulsar vs. RabbitMQ: Which is Fastest?
The OpenMessaging Benchmark Framework
The Pathologies of Big Data - ACM Queue
Efficient data transfer through zero copy - IBM Developer
本文为原创文章,转载请附上原文出处链接:https://www.cnblogs.com/ZhangZiSheng001/p/16788561.html
标签:
留言评论