Spring 事务
1、JDBC事务控制
不管你现在使用的是那一种ORM开发框架,只要你的核心是JDBC,那么所有的事务处理都是围绕着JDBC开展的,而JDBC之中的事务控制是由Connection接口提供的方法:
- 1、关闭自动事务提交:connection.setAutoCommit(false);
- 2、事务手工提交: connection.commit();
- 3、事务回滚: connection.rollback();
在程序的开发之中事务的使用是存在有
前提的:如果某一个业务现在需要同时执行若干条数据更新处理操作,这个时候才会使用到事务控制,除此之外是不需要强制性处理的。

按照传统的事务控制处理方法来讲一般都是在业务层进行处理的,而在之前分析过了如何基于AOP 设计思想采用
动态代理设计模式实现的事务处理模型,这种操作可以在不侵入业务代码的情况下进行事务的控制,但是代码的实现过程实在是繁琐,现在既然都有了AOP处理模型了,所以对于事务的控制就必须有一个完整的加强。
1.1、ACID事务原则
ACID主要指的是事务的四种特点:原子性(Atomicity)、一致性(Consistency)、隔离性或独立性(lsolation)、持久性(Durabilily)四个特征:
- 原子性(Atomicity):整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样;
- 一致性(Consistency):一个事务可以封装状态改变(除非它是一个只读的)。事务必须始终保持系统处于一致的状态,不管在任何给定的时间并发事务有多少;
- 隔离性(lsolation):隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。如果有两个事务,运行在相同的时间内,执行相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统;
- 持久性(Durability):在事务完成以后,该事务对数据库所作的更改便持久的保存在数据库之中,并不会被
回滚。
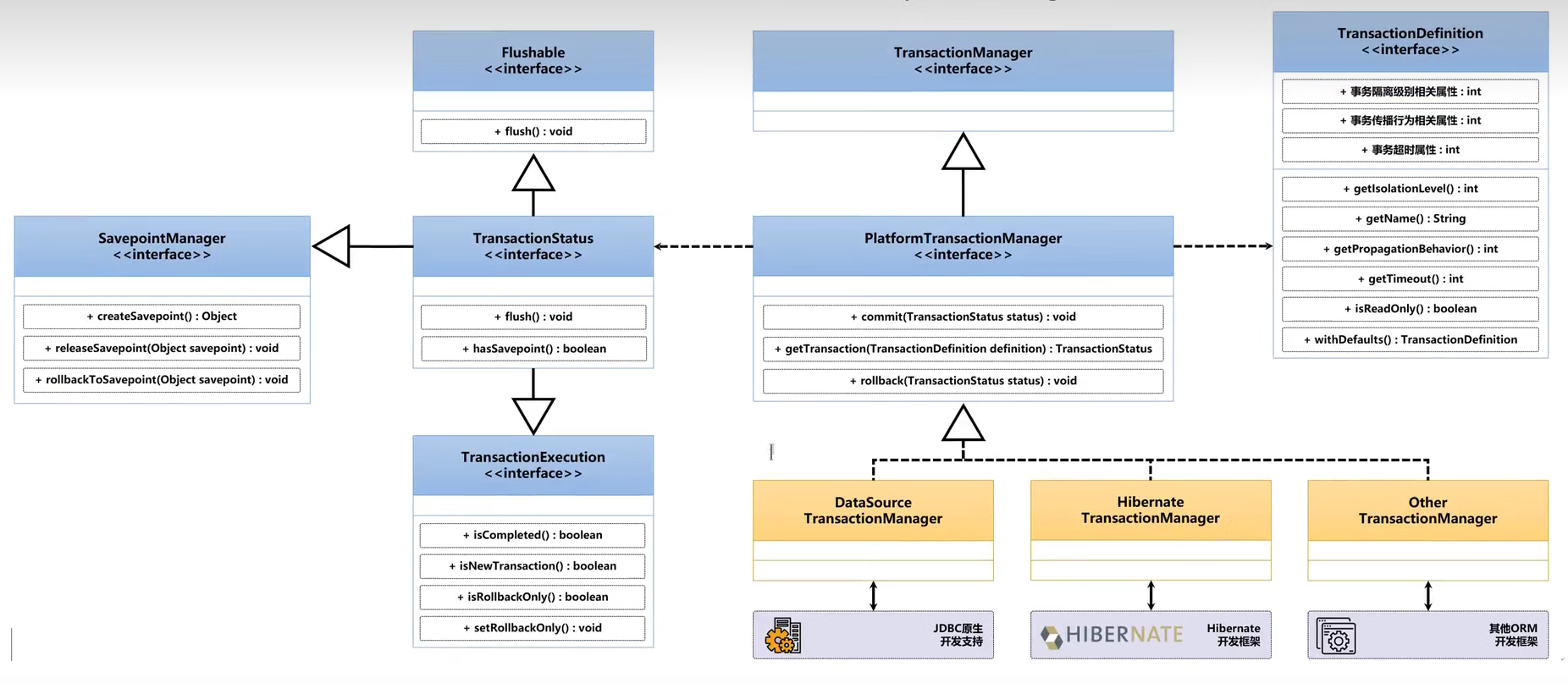
2、Spring事务架构
Spring事务是对已有JDBC事务的进一步的包装型处理,所以底层依然是
JDBC事务控制,而后在这之上进行了更加合理的二次开发与设计,首先先来看一下Spring 与JDBC事务之间的结构图。

只要是说到了事务的开发,那么就必须考虑到ORM组件的整合问题各类的ORM开发组件实在是太多了,同时Spring在设计的时候无法预知未来,那么这个时候在
Spring 框架里面就针对于事务的接入提供了一个开发标准。 Spring事务的核心实现关键是在于:PlatformTransactionManager

通过以上的代码可以发现,PlatfrmTransactionManager接口存在有一个TransactionManager父接口,下面打开该接口的定义来观察其具体功能。

在现代的开发过程之中,最为核心的事务接口主要使用的是PlatformTransactionManager(这也就是长久以来的习惯),在Spring最早出现声明式事务的时候,就有了这个处理接口了。在进行获取事务的时候可以发现getTransaction()方法内部需要接收有一个TransactionDefinition接口实例,这个接口主要定义了
Spring事务的超时时间,以及Spring事务的传播属性(是面试的关键所在),而在getTransaction()方法内部会返回有一个TransactionStatus接口实例,打开这个接口来观察一下。.
public interface TransactionStatus extends TransactionExecution, SavepointManager, Flushable {
boolean hasSavepoint(); // 是否存在hasSavepoint (事务保存点)
void flush(); // 事务刷新
}
而后该接口内部定义的时候又需要继承TransactionExecution、SavepointManager(事务保存点管理器)、Flushable(事务刷新)三个父接口。下图就是Spring事务的整体架构。
3、编程式事务控制
由于现在很少用到这种编程式事务了,导致很多初学者根本不知道这其中是怎么配置的。其实万变不离其宗,都是基于JDBC的事务控制。
- 使用步骤
- 配置事务-》 是数据源
- 编写代码 控制事务
3.1如何使用
数据源使用的是文章开始前的SpringJDBC的环境 地址
1 配置事务
public class TransactionConfig {
@Bean
public PlatformTransactionManager transactionManager(DataSource dataSource) {
// PlatformTransactionManager 类似于一个事务定义的标准
// DataSource 也是一个标准 规范数据源
DataSourceTransactionManager transactionManager =
new DataSourceTransactionManager(dataSource);
// transactionManager.setDataSource(dataSource); 二选一即可
return transactionManager;
}
}
面试题: PlatformTransactionManager 与 TransactionManager两者区别?
TransactionManager是后爹,是属于PlatformTransactionManager父接口,但是现在不要轻易使用,因为很多的传统的Spring开发项目还是使用的是PlatformTransactionManager。TransactionManager是为响应式编程做的准备。
2 编写代码
@Test
public void testInsert() {
String sql = "insert into yootk.book(title,author,price) values(?,?,?)";
LOGGER.info("【插入执行结果】:{}", jdbcTemplate.update(sql, "Python入门", "李老师", 99.90));
LOGGER.info("【插入执行结果】:{}", jdbcTemplate.update(sql, "Java入门", null, 99.90));
LOGGER.info("【插入执行结果】:{}", jdbcTemplate.update(sql, "Js入门", "李老师", null));
}

执行代码后会发现,出现异常提示信息。由于我们的表中配置了not null,所以在插入是会出现异常。这也就是我们异常信息的来源。
- 由于出现了异常,可是,数据还是插入到数据库,在正常开发中是不允许这样的情况发现的,那么该如何解决呢。还记得上面配置的事务信息吗。修改测试类如下:

@Test
public void testInsert() {
String sql = "insert into yootk.book(title,author,price) values(?,?,?)";
TransactionStatus status = transactionManager.getTransaction( //开启事务
new DefaultTransactionAttribute()); // 默认事务属性
try {
LOGGER.info("【插入执行结果】:{}", jdbcTemplate.update(sql, "Python入门", "李老师", 99.90));
LOGGER.info("【插入执行结果】:{}", jdbcTemplate.update(sql, "Java入门", null, 99.90));
LOGGER.info("【插入执行结果】:{}", jdbcTemplate.update(sql, "Js入门", "李老师", null));
transactionManager.commit(status); // 提交
} catch (DataAccessException e) {
transactionManager.rollback(status); // 回滚
throw new RuntimeException(e);
}
}
注意:执行先,需要先将数据库表清空,能更好的观察执行结果。
- 而后会发现,虽然我们的程序执行出现异常了,但数据库没有数据。
- 说明我们配置的事务生效了,使其出现异常,回滚了。

3.2TransactionStatus
如果现在仅仅是使用了TransactionManager提交和回滚的处理方法,仅仅是Spring提供的事务处理的皮毛所在,而如果要想深入的理解事务处理的特点,那么就需要分析其每一个核心的组成类,首先分析的就是TransactionStatus。

在开启事务的时候会返回有一个TransactionStatus接口实例,而后在提交或回滚事务的时候都需要针对于指定的status实例进行处理,首先来打开这个接口的定义关联结构。
DefaultTransactionStatus是TransactionStatus默认实现的子类而后该类并不是直接实例化的,而是通过事务管理器负责实例化处理的,status所得到的是一个事务的处理标记,而后Spring依照此标记管理事务。
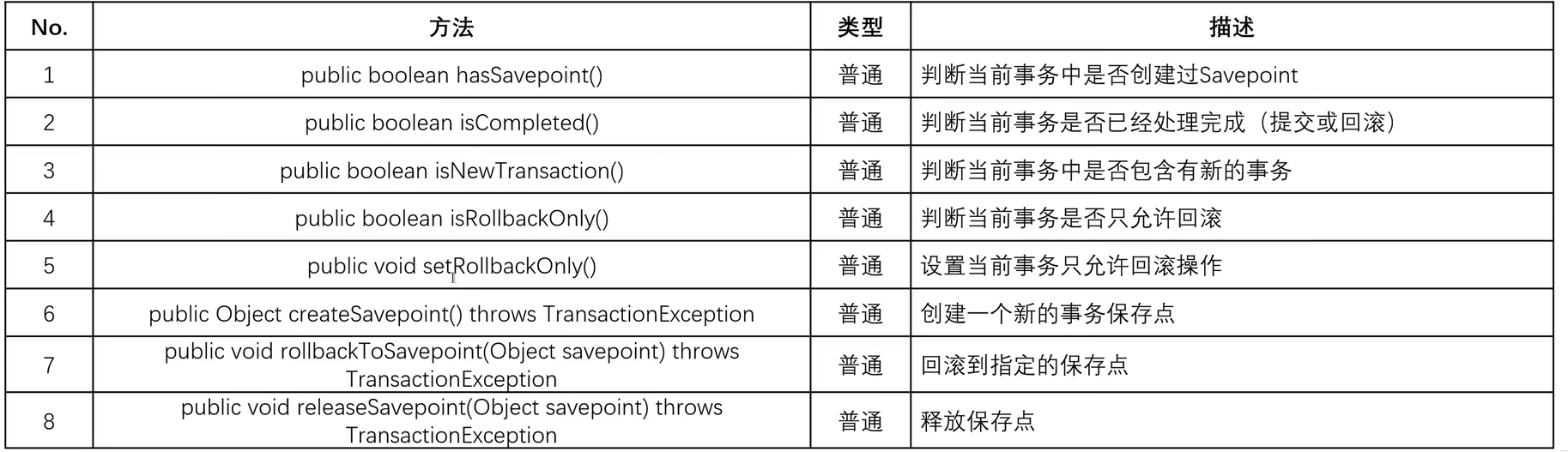
现我们有以下业务,在业务执行过程中,有一部分业务执行失败,正常来说,是执行回滚操作,但是现在我们要让某一个位置之前的执行的sql不回滚。那么这个功能如何实现呢?
这里就需要用到我们事务的保存点:
@Test
public void testInsertSavePoint() { // 测试事务的保存点
String sql = "insert into yootk.book(title,author,price) values(?,?,?)";
TransactionStatus status = transactionManager.getTransaction( // 开启事务
new DefaultTransactionAttribute()); // 默认事务属性
Object savepointA = null; //保存点
try {
LOGGER.info("【插入执行结果】:{}", jdbcTemplate.update(sql, "Python入门", "李老师", 99.90));
savepointA = status.createSavepoint(); // 创建保存点
LOGGER.info("【插入执行结果】:{}", jdbcTemplate.update(sql, "Java入门", null, 99.90));
transactionManager.commit(status); // 正常执行 事务提交
} catch (DataAccessException e) {
// 出现异常 先回滚到保存点 然后在提交保存点之前的事务
status.releaseSavepoint(savepointA); // 回滚到保存点
transactionManager.commit(status); // 提交
throw new RuntimeException(e);
}
}
4、Spring事务隔离级别
Spring面试之中隔离级别的面试问题是最为常见的,也是一个核心的基础所在,但是所谓的隔离级别一定要记住,是在
并发环境访问下才会存在的问题。数据库是一个项目应用中的公共存储资源,所以在实际的项目开发过程中,很有可能会有两个不同的线程(每个线程拥有各自的数据库事务),要进行同一条数据的读取以及更新操作。
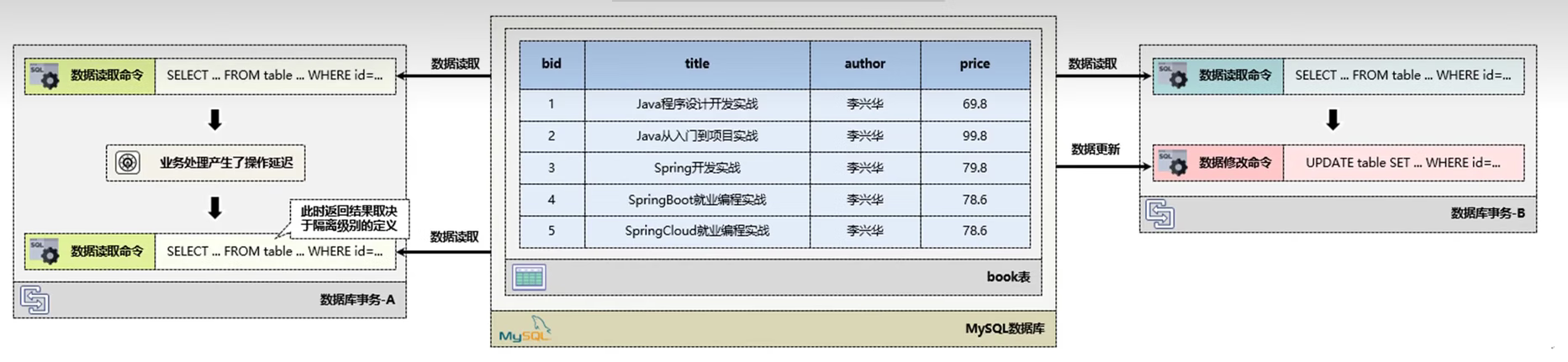
下面就通过代码的形式 一步步的揭开他的庐山真面目。
- 对于事务,
private class BookRowMapper implements RowMapper<Book> { // 对象映射关系
@Override
public Book mapRow(ResultSet rs, int rowNum) throws SQLException {
Book book = new Book();
book.setBid(rs.getInt(1));
book.setTitle(rs.getString(2));
book.setAuthor(rs.getString(3));
book.setPrice(rs.getDouble(4));
return book;
}
}
@Test
public void testInsertIsolation() throws InterruptedException { // 测试事务的隔离级别
String query = "select bid,title,author,price from yootk.book where bid = ?"; // 查询
String update = "update yootk.book set title = ?, author =? where bid =?"; // 根据id修改
BookRowMapper bookRowMapper = new BookRowMapper(); // 对Book对象的映射
DefaultTransactionDefinition definition =
new DefaultTransactionDefinition(); // 创建默认事务对象
Thread threadA = new Thread(() -> {
TransactionStatus statusA = this.transactionManager.getTransaction(definition); //开始事务
Book book = this.jdbcTemplate.queryForObject(query, bookRowMapper, 1); // 查询bid = 1的数据
String name = Thread.currentThread().getName();// 获取线程名称
System.out.println(11111 + "??????");
LOGGER.info("{}【查询结果】:{}", name, book);
try {
TimeUnit.SECONDS.sleep(2); //等待两秒 让线程B修改之后再查询
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
book = jdbcTemplate.queryForObject(query, bookRowMapper, 1); // 再次查询
LOGGER.info("{}【查询结果】:{}", name, book);
}, "事务线程-A");
Thread threadB = new Thread(() -> {
TransactionStatus statusB =
transactionManager.getTransaction(definition); // 开启事务
String name = Thread.currentThread().getName();// 获取线程名称
int i = 0;
try {
i = jdbcTemplate.update(update, "Netty", "李老师", 1);
LOGGER.info("{} 执行结果:{}", name, i);
transactionManager.commit(statusB); // 提交事务
} catch (DataAccessException e) {
transactionManager.rollback(statusB); // 回滚事务
throw new RuntimeException(e);
}
}, "事务线程-B");
threadB.start();// 启动线程
threadA.start();
threadA.join();// 等待相互执行完成
threadB.join();
}
执行结果
事务线程-A【查询结果】:Book(bid=1, title=Netty, author=李老师, price=99.9)
事务线程-B 执行结果:1
事务线程-A【查询结果】:Book(bid=1, title=Netty, author=李老师, price=99.9)
查看执行结果可知,我们线程B执行的是更新操作,但是更新成功后,在事务A进行查询时,本应是我们更新后的数据,这才对呀。所以这个事务出现了事务不同步的问题。
为了保证并发状态下的数据读取的正确性,就需要通过事务的隔离级别来进行控制,实际上控制的就是脏读、幻读以及不可重复读的问题了。
4.1、脏读
脏读(Dirty reads):事务A在读取数据时,读取到了事务B未提交的数据,由于事务B有可能被回滚,所以该数据有可能是一个无效数据
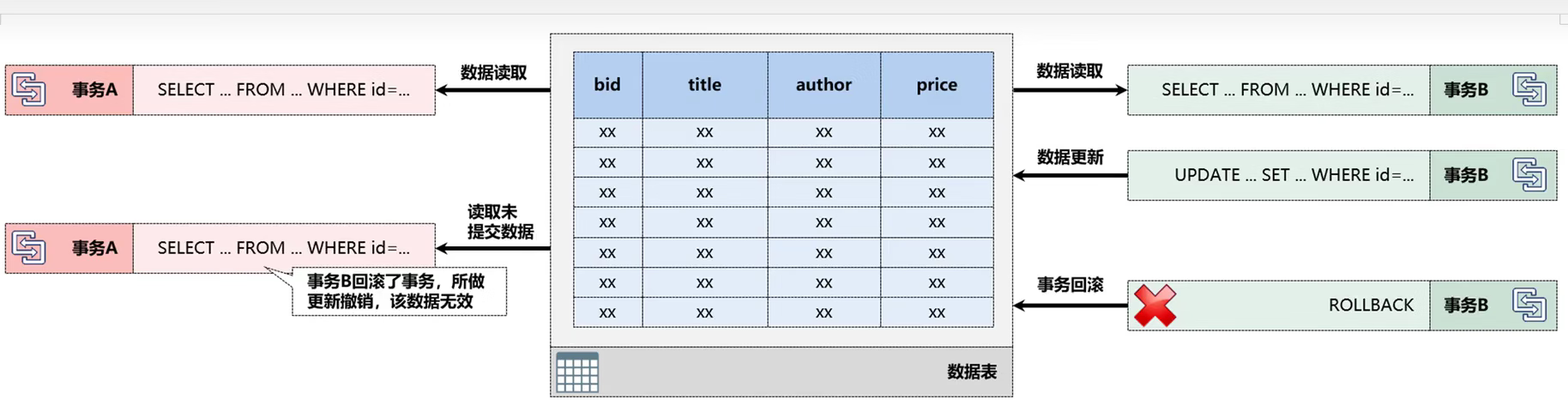
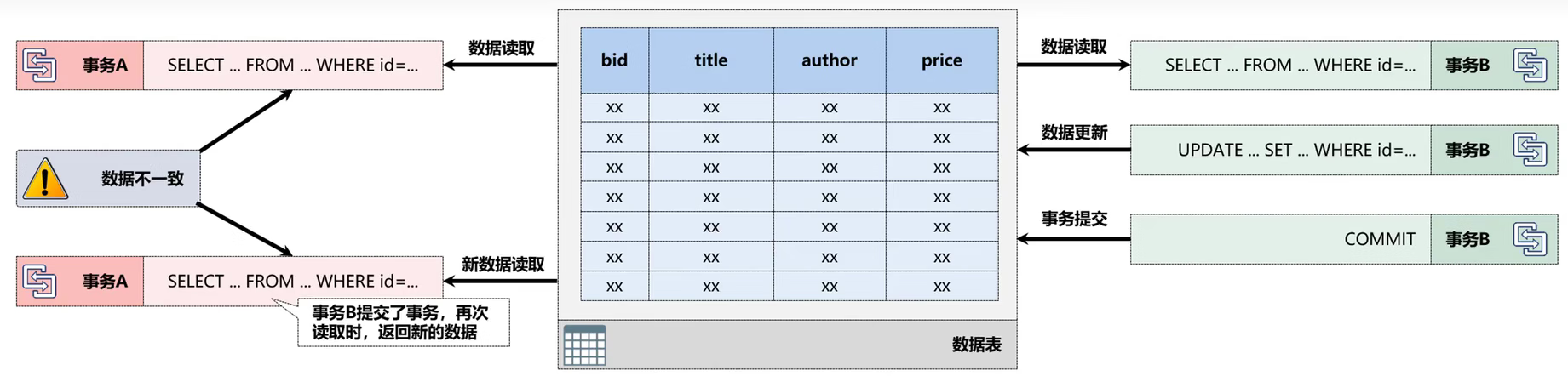
4.2、不可重复读
不可重复读(Non-repeatable Reads):事务A对一个数据的两次读取返回了不同的数据内容,有可能在两次读取之间事务B对该数据进行了修改,一般此类操作出现在数据修改操作之中;
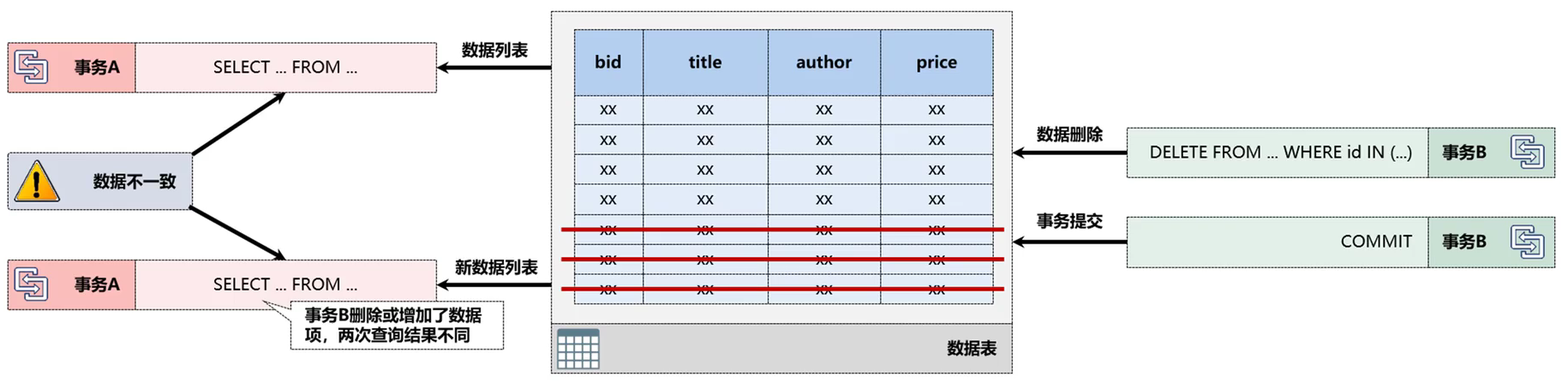
4.3、幻读
幻读(Phantom Reads):事务A在进行数据两次查询时产生了不一致的结果,有可能是事务B在事务A第二次查询之前增加或删除了数据内容所造成的.
Spring最大的优势是在于将所有的配置过程都进行了标准化的定义,于是在TransactionDefintion接口里面就提供了数据库隔离级别的定义常量。
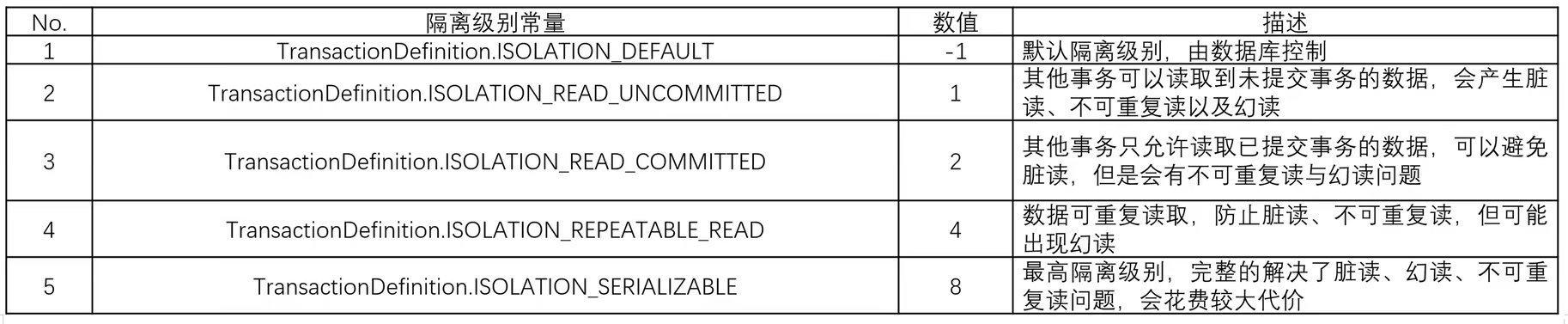
从正常的设计角度来讲,在进行Spring事务控制的时候,不要轻易的去随意修改隔离级别(需要记住这几个隔离级别的概念),因为一般都使用默认的隔离级别,由数据库自己来实现的控制。
【MySQL数据库】查看MySQL数据库之中的默认隔离级别
SHOW VARIABLES LIKE 'transaction_isolation';
举个栗子,来看看隔离级别的作用吧
修改testInsertIsolation测试类
definition.setIsolationLevel(TransactionDefinition.ISOLATION_READ_COMMITTED);// 设置事务隔离级别为:读已提交
执行结果:
因为我们线程B在修改后,就提交了,而我们设置的隔离级别是读已提交,所以能读到已提交的数据
事务线程-A【查询结果】:Book(bid=1, title=Java入门到入土, author=李老师, price=99.9)
事务线程-B 执行结果:1
事务线程-A【查询结果】:Book(bid=1, title=Netty, author=李老师, price=99.9)
5、Spring事务传播机制
事务开发是和业务层有直接联系的,在进行开发的过程之中,很难出现业务层之间不互相调用的场景,例如:存在有一个A业务处理,但是A业务在处理的时候有可能会调用B业务,那么如果此时A和B之间各自都存在有事务的机制,那么这个时候就需要进行事务有效的传播管理。
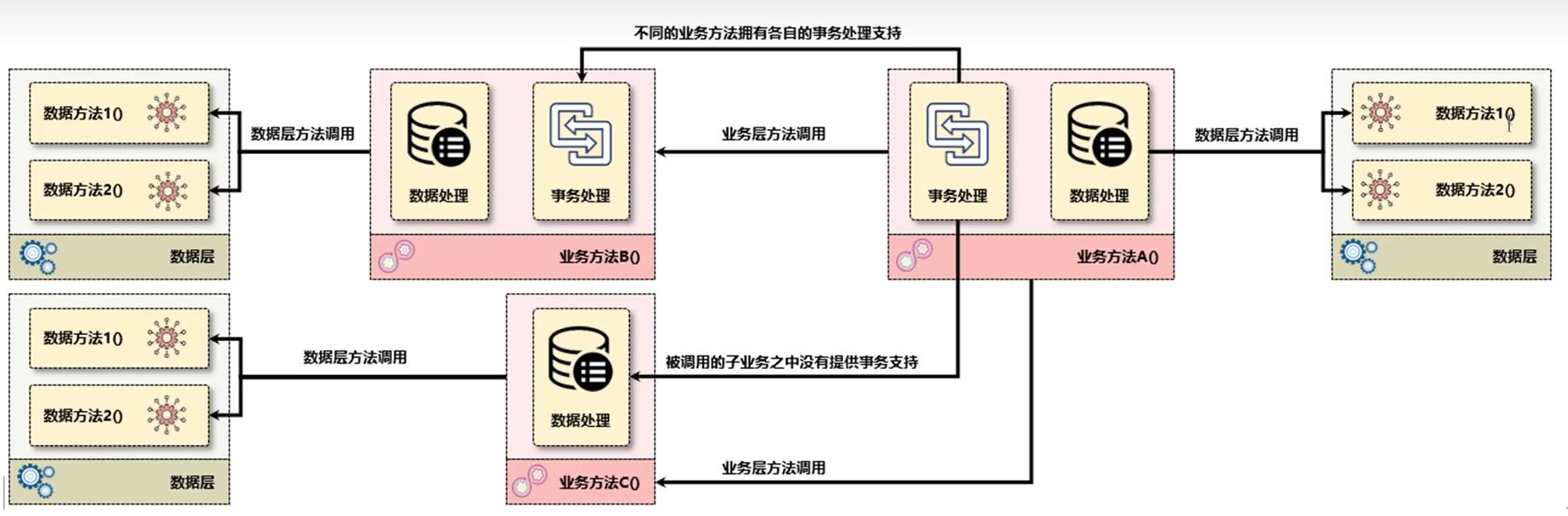
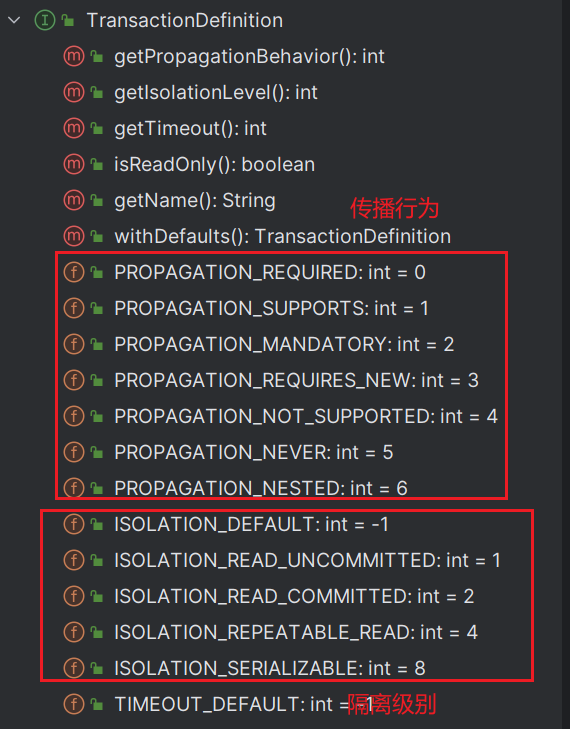
1、TransactionDefinition.PROPAGATION_REQUIRED:默认事务隔离级别,子业务直接支持当前父级事务,如果当前父业务之中没有事务,则创建一个新的事务,如果当前父业务之中存在有事务,则合并为一个完整的事务。简化的理解:不管任何的时候,只要进行了业务的调用,都需要创建出一个新的事务,这种机制是最为常用的事务传播机制的配置。
2、TransactionDefinition.PROPAGATION_SUPPORTS:如果当前父业务存事务,则加入该父级事务。如果当前不存在有父级事务,则以非事务方式运行;
3、TransactionDefinition.PROPAGATION_NOT_SUPPORTED:以非事务的方式运行,如果当前存在有父级事务,则先自动挂起父级事务后运行;
4、TransactionDefinition.PROPAGATION_MANDATORY:如果当前存在父级事务,则运行在父级事务之中,如果当前无事务则抛出异常(必须存在有父级事务);
5、TransactionDefinition.PROPAGATION_REQUIRES_NEW:建立一个新的子业务事务,如果存在有父级事务则会自动将其挂起,该操作可以实现子事务的独立提交,不受调用者的事务影响,即便父级事务异常,也可以正常提交;
6、TransactionDefinition.PROPAGATION_NEVER:以非事务的方式运行,如果当前存在有事务则抛出异常;
7、TransactionDefinition.PROPAGATION_NESTED:如果当前存在父级事务,则当前子业务中的事务会自动成为该父级事务中的一个子事务,只有在父级事务提交后才会提交子事务。如果子事务产生异常则可以交由父级调用进行异常处理,如果父级事务产生异常,则其也会回滚。
标签:
留言评论