众所周知HashMap是工作和面试中最常遇到的数据类型,但很多人对HashMap的知识止步于会用的程度,对它的底层实现原理一知半解,了解过很多HashMap的知识点,却都是散乱不成体系,今天一灯带你一块深入浅出的剖析HashMap底层实现原理。
看下面这些面试题,你能完整的答对几道?
1. HashMap底层数据结构?
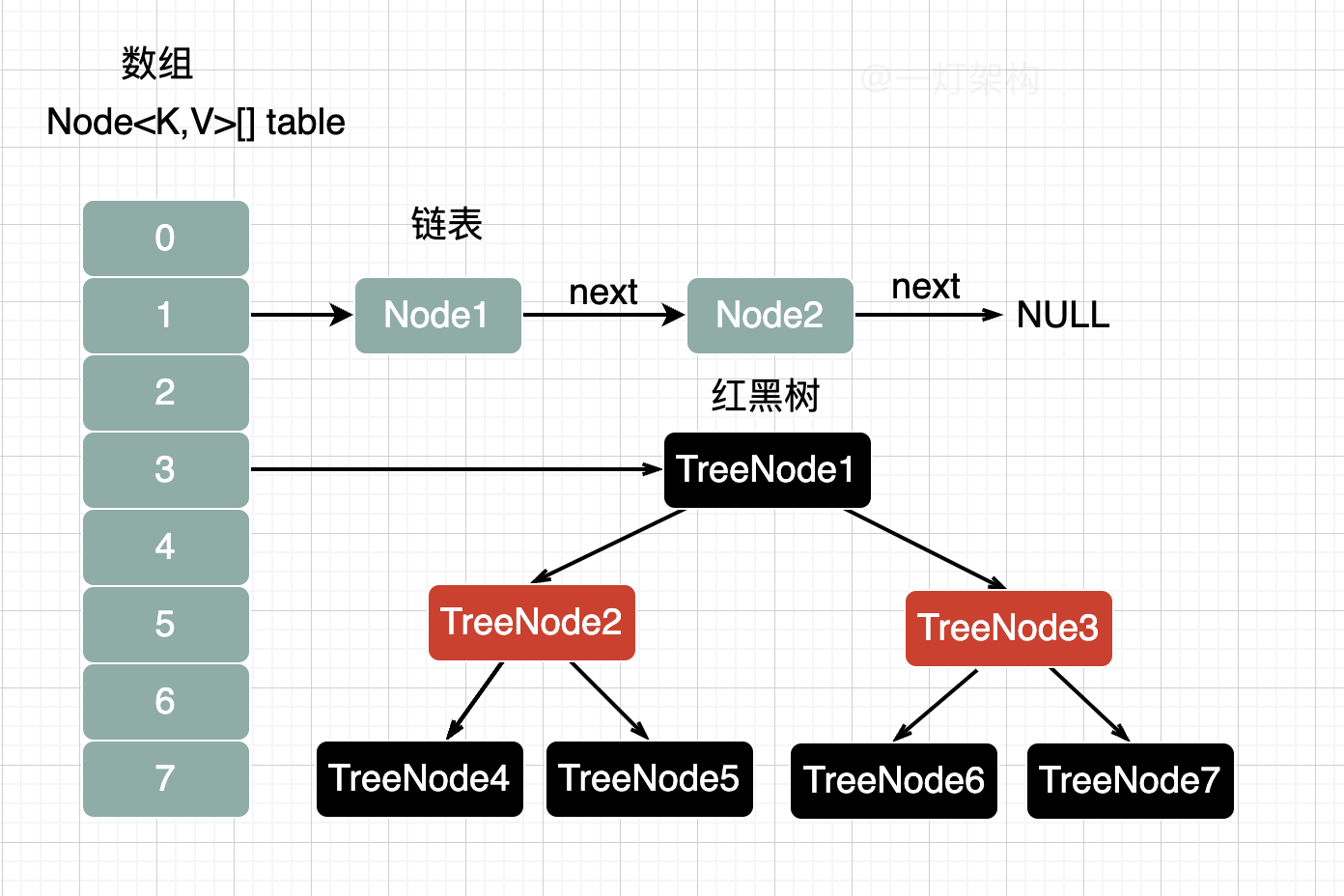
JDK1.7采用的是数组+链表,数组可以通过下标访问,实现快速查询,链表用来解决哈希冲突。
链表的查询时间复杂度是O(n),性能较差,所以JDK1.8做了优化,引入了红黑树,查询时间复杂度是O(logn)。
JDK1.8采用的是数组+链表+红黑树的结构,当链表长度大于等于8,并且数组长度大于等于64时,链表才需要转换成成红黑树。
2. HashMap的初始容量是多少?
如果面试的时候,你回答是16,面试官肯定让你回去等通知。
JDK1.7的时候初始容量确实是16,但是JDK1.8的时候初始化HashMap的时候并没有指定容量大小,而是在第一次执行put数据,才初始化容量。
// 负载因子大小
final float loadFactor;
// 默认负载因子大小
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 初始化方法
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
执行new HashMap()方法初始化的时候,只指定了负载因子的大小。
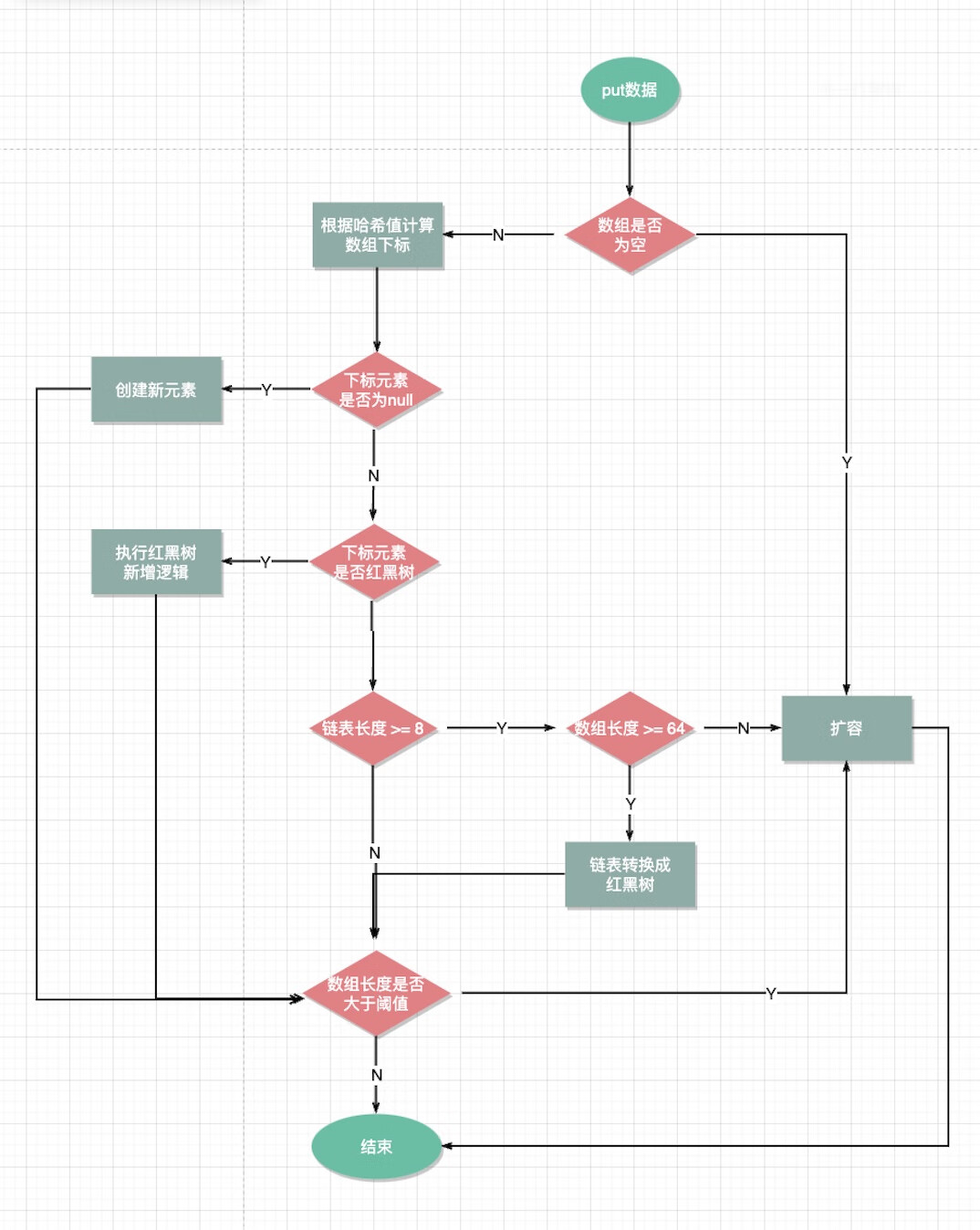
3. HashMap的put方法流程?
- 计算key的哈希值
- 判断数组是否为空,如果为空,就执行扩容,初始化数据大小。
- 如果数组不为空,根据哈希值找到数组所在下标
- 判断下标元素是否为null,如果为null就创建新元素
- 如果下标元素不为null,就判断是否是红黑树类型,如果是,则执行红黑树的新增逻辑
- 如果不是红黑树,说明是链表,就追加到链表末尾
- 如果判断链表长度是否大于等于8,数组长度是否大于等于64,如果不是就执行扩容逻辑
- 如果是,则需要把链表转换成红黑树
- 最后判断新增元素后,判断元素个数是否大于阈值(16*0.75=12),如果是则执行扩容逻辑,结束。
源码如下:
// put方法入口
public V put(K key, V value) {
// 计算哈希值
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 判断数组是否为空,为空的话,则进行扩容初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 计算数组下标位置,判断下标位置元素是否为null
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 数组中已经存在元素(处理哈希冲突)
else {
Node<K,V> e; K k;
// 判断元素值是否一样,如果一样则替换旧值
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 判断元素类型是否是红黑树
else if (p instanceof TreeNode)
// 执行红黑树新增逻辑
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 不是红黑树类型则说明是链表
else {
// 遍历链表
for (int binCount = 0; ; ++binCount) {
// 到达链表的尾部
if ((e = p.next) == null) {
// 在尾部插入新结点
p.next = newNode(hash, key, value, null);
// 链表结点数量达到阈值(默认为 8 ),执行 treeifyBin 方法
// 这个方法会根据 HashMap 数组来决定是否转换为红黑树。
// 只有当数组长度大于或者等于 64 的情况下,才会执行转换红黑树操作,以减少搜索时间。否则,就是只是对数组扩容。
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
// 判断链表中结点的key值与插入的元素的key值是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 相等,跳出循环
break;
// 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表
p = e;
}
}
// 表示在数组中找到key值、哈希值与插入元素相等的结点
if (e != null) {
// 记录e的value
V oldValue = e.value;
// onlyIfAbsent为false或者旧值为null
if (!onlyIfAbsent || oldValue == null)
//用新值替换旧值
e.value = value;
// 访问后回调
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}
// 记录修改次数
++modCount;
// 元素个数大于阈值则扩容
if (++size > threshold)
resize();
// 插入后回调
afterNodeInsertion(evict);
return null;
}
4. HashMap容量大小为什么要设置成2的倍数?
int index = hash(key) & (n-1);
为了更快的计算key所在的数组下标位置。
当数组长度(n)是2的倍数的时候,就可以直接通过逻辑与运算(&)计算下标位置,比取模速度更快。
5. HashMap为什么是线程不安全?
原因就是HashMap的所有修改方法都没有加锁,导致在多线程情况下,无法保证数据一致性和安全性。
比如:一个线程删除了一个key,由于没有加锁,其他线程无法及时感知到,还继续能查到这个key,无法保证数据的一致性。
比如:一个线程添加完一个元素,由于没有加锁,其他线程无法及时感知到,另一个线程正在扩容,扩容后就把上一个线程添加的元素弄丢了,无法保证数据的安全性。
6. 解决哈希冲突方法有哪些?
常见有链地址法、线性探测法、再哈希法等。
链地址法
就是把发生哈希冲突的值组成一个链表,HashMap就是采用的这种。
线性探测法
发生哈希冲突后,就继续向下遍历,直到找到空闲的位置,ThreadLocal就是采用的这种,以后再详细讲。
再哈希法
使用一种哈希算法发生了冲突,就换一种哈希算法,直到不冲突为止(就是这么聪明)。
7. JDK1.8扩容流程有什么优化?
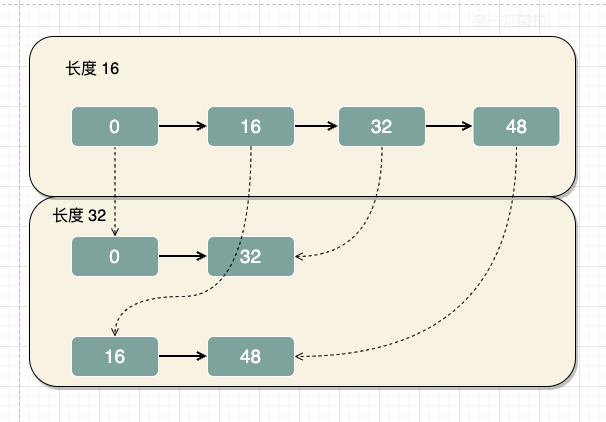
在JDK1.7扩容的时候,会遍历原数组,重新哈希,对新数组长度逻辑与,计算出数据下标,然后放到新数组中,比较麻烦耗时。
在JDK1.8扩容的时候,会遍历原数组,然后统计出两组数据,一组是新数组的下标位置不变,另一组是新数组的下标位置等于原数组的下标位置加上原数组的长度。
比如:数组长度由16扩容到32,哈希值是0和32的元素,在新旧数组中下标位置不变,都是下标为0的位置。而哈希值是16和48的元素,在新数组的位置=原数组的下标+原数组的长度,也就是下标为16的位置。

标签:
留言评论