@
概述
定义
HBase 官网地址 https://hbase.apache.org/
HBase 官网文档 https://hbase.apache.org/book.html
HBase GitHub源码地址 https://github.com/apache/hbase
Apache HBase是以HDFS为数据存储分布式的、可伸缩的Hadoop NoSQL数据库。最新版本为2.5.0
HBase支持对大数据进行随机、实时的读写访问,可以在商用硬件集群上托管非常大的表——数十亿行X数百万列。Apache HBase是一个开源的、分布式的、版本化的、非关系数据库,模仿了谷歌开发的Bigtable结构化数据的分布式存储系统,与Bigtable利用了谷歌文件系统提供的分布式数据存储一样,Apache HBase在Hadoop和HDFS的基础上提供了类似Bigtable的功能。
特点
可扩展性。
读写严格一致。
自动和可配置的表分片。
regionserver之间的自动故障转移支持。
使用Apache HBase表支持Hadoop MapReduce作业。
易于使用Java API进行客户端访问。
块缓存和Bloom过滤器用于实时查询。
通过服务器端过滤器下推查询谓词。
Thrift网关和一个支持XML、Protobuf和二进制数据编码选项的rest Web服务。
可扩展的基于jruby (JIRB)的shell。
支持通过Hadoop指标子模块导出指标。
数据模型
概述
HBase的设计理念依据Coogle 的BigTable论文,论文中说到Bigtable 是一个稀疏的,分布式的,持久的多维排序map。
映射由行键,列键和时间戳索引;映射中的每一个值都是一个未解释的字节数组。
HBase数据模型和BigTable的对应关系如下
HBase 使用于 BigTable非常相似的数据模型,用户将数据行存储在带标签的表中,数据行具有可排序的键和任意数量的列。
该表存储稀疏,因此如果用户喜欢,同一表中的行可以具有疯狂变化的列
HBase 数据模型的关键在于稀疏、分布式、多维、排序的映射。其中映射 map 指代非关系型数据库的 key-Value 结构。
逻辑结构
HBase 可以用于存储多种结构的数据,以 JSON 为例:
逻辑结构存储数据稀疏,数据存储多维,不同的行具有不同的列。数据存储整体有序,按照RowKey的字典序排列,RowKey为Byte数组,示例如下:
物理存储结构
物理存储结构即为数据映射关系,而在概念视图的空单元格,底层实际根本不储存。
数据模型
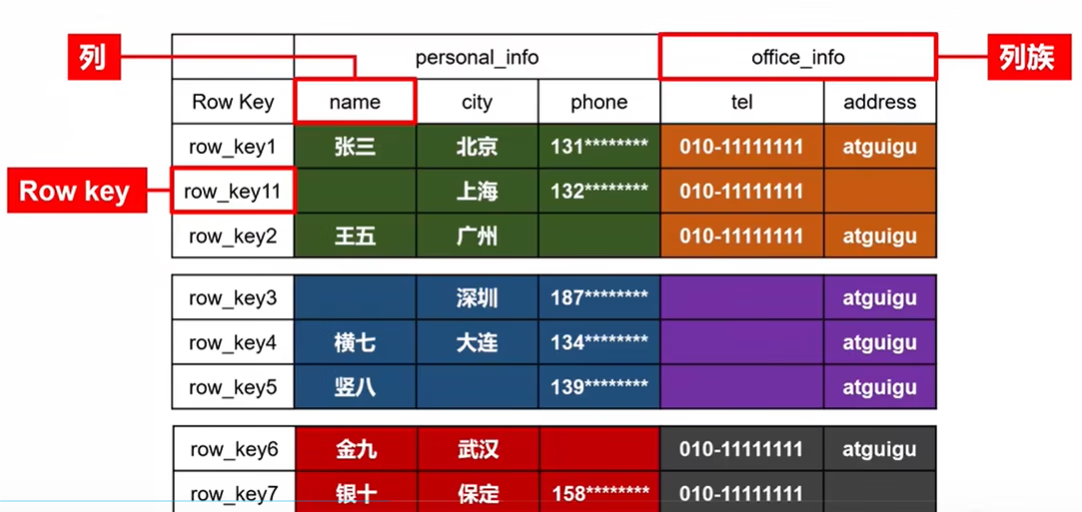
Name Space:命名空间,类似于关系型数据库的 database 概念,每个命名空间下有多个表。HBase 两个自带的命名空间,分别是 hbase 和default,hbase 中存放的是 HBase 内置的表,default表是用户默认使用的命名空间。
Table:类似于关系型数据库的表概念。不同的是,HBase 定义表时只需要声明列族即可,不需要声明具体的列。因为数据存储时稀疏的,所有往 HBase 写入数据时,字段可以动态、按需指定。因此和关系型数据库相比,HBase 能够轻松应对字段变更的场景。
Row:HBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey 的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重要。
Column:HBase 中的每个列都由 Column Family(列族)和 Column Qualifier(列限定符)进行限定,例如 info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
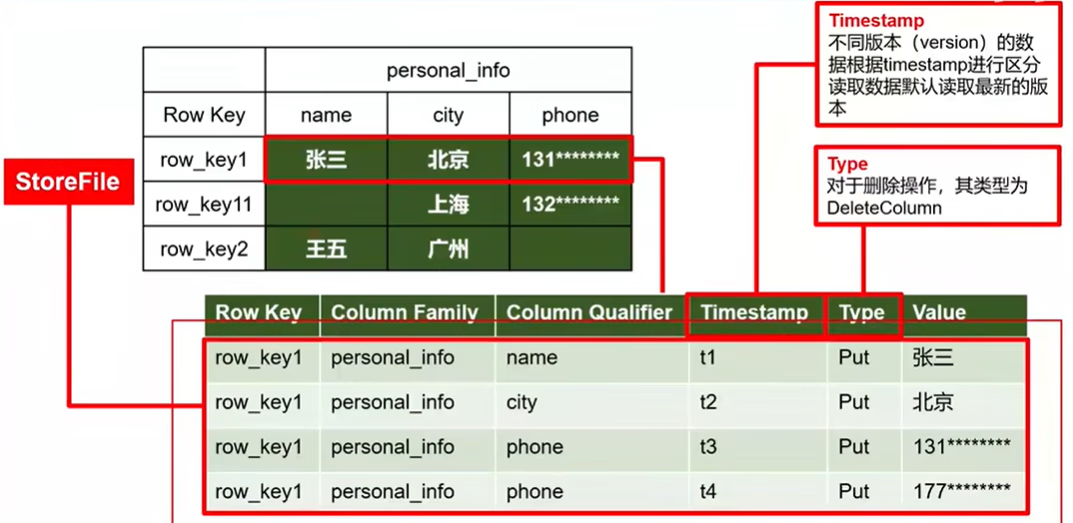
Time Stamp:用于标识数据的不同版本(version),每条数据写入时,系统会自动为其加上该字段, 其值为写入 HBase 的时间。
Cell:由{rowkey, column Family:column Qualifier, timestamp} 唯一确定的单元。cell 中的数据全部是字节码形式存储。
应用场景
对象存储:比如一些app的海量的图片、网页、新闻等对象,可以存储在HBase中,有些病毒公司的病毒库也可以存储在HBase中。
时空数据:主要是轨迹、气象网格之类
比如滴滴打车的轨迹数据主要存在HBase之中。
另外大数据量的车联网企业,数据也都是存在HBase中。
比如互联网出行,智慧物流与外卖递送,传感网与实时GIS等场景。
时序数据:时序数据就是分布在时间上的一系列数值。
HBase之上有OpenTSDB模块,可以满足时序类场景的需求。
比如我们有很多的设备、传感器,产生很多数据,如果规模不是特别大的厂家有几千个风机,每个风机有几百个指标,那么就会有一百万左右的时序数据,如果用采样每一秒会产生一百万个时间点,如果用传统数据库,那么每一秒会产生一百万次,持续地往MQ做一百万次,它会崩裂。并且查询也是个大问题,除了多维查询以外,我们还会额外地增加时间纬度,查看一段时间的数据。这时候HBase很好了满足了时序类场景的需求。
推荐画像:特别是用户的画像,是一个比较大的稀疏矩阵,蚂蚁的风控就是构建在HBase上。用户画像有用户数据量大,用户标签多,标签统计维度不确定等特点,适合HBase特性的发挥。
消息/订单:在电信领域、银行领域,不少的订单查询底层的存储,另外不少通信、消息同步的应用构建在HBase之上。
Feed流:是RSS中用来接收该信息来源更新的接口,简单的说就是持续更新并呈现给用户的内容。比如微信朋友圈中看到的好友的一条条状态,微博看到的你关注的人更新的内容,App收到的一篇篇新文章的推送,都算是feed流。
NewSQL:HBase上有Phoenix的插件,可以满足二级索引、SQL的需求,对接传统数据需要SQL非事务的需求。从NoSQL到NewSQL,Phoenix或许是新的趋势。
基础架构
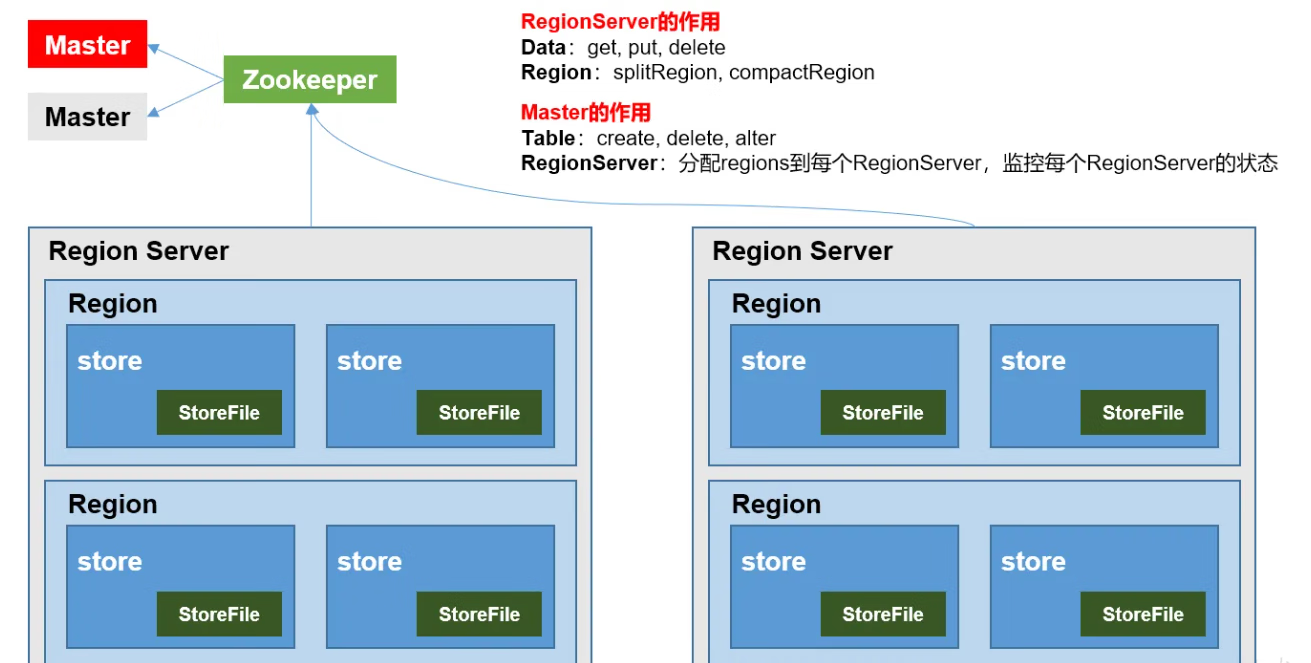
组成角色包含如下几个部分:
Master:实现类为 HMaster,负责监控集群中所有的 RegionServer 实例。
LoadBalancer 负载均衡器:周期性监控 region 分布在 regionServer 上面是否均衡,由参数 hbase.balancer.period 控 制周期时间,默认 5 分钟。
CatalogJanitor 元数据管理器:定期检查和清理 hbase:meta 中的数据。meta 表内容在进阶介绍。
MasterProcWAL master 预写日志处理器:把 master 需要执行的任务记录到预写日志 WAL 中,如果 master 宕机,让 backupMaster 读取日志继续干。
管理元数据表格 hbase:meta,接收用户对表格创建修改删除的命令并执行
监控 region 是否需要进行负载均衡,故障转移和 region 的拆分。
主要作用如下:
管理元数据表格 hbase:meta,接收用户对表格创建修改删除的命令并执行。
监控 region 是否需要进行负载均衡,故障转移和 region 的拆分。
通过启动多个后台线程监控实现上述功能:
Region Server:Region Server 实现类为 HRegionServer,主要作用如下:
负责数据 cell 的处理,例如写入数据 put,查询数据 get 等。
拆分合并 region 的实际执行者,有 master 监控,有 regionServer 执行。
Zookeeper:HBase 通过 Zookeeper 来做 master 的高可用、记录 RegionServer 的部署信息、并且存储 有 meta 表的位置信息。 HBase 对于数据的读写操作时直接访问 Zookeeper 的,在 2.3 版本推出 Master Registry 模式,客户端可以直接访问 master。使用此功能,会加大对 master 的压力,减轻对 Zookeeper 的压力。
HDFS:HDFS 为 Hbase 提供最终的底层数据存储服务,同时为 HBase 提供高容错的支持。
安装
前置条件
Zookeeper(使用前面文章已部署集群)
HDFS(使用前面文章已部署集群)
部署
修改conf目录下配置文件vim conf/hbase-site.xml
修改regionservers配置vim conf/regionservers
将Hadoop的配置文件core-site.xml和hdfs-site.xml拷贝到HBase的conf目录下
分发HBase目录到其他两个节点上
启动服务
群启后查看服务进程
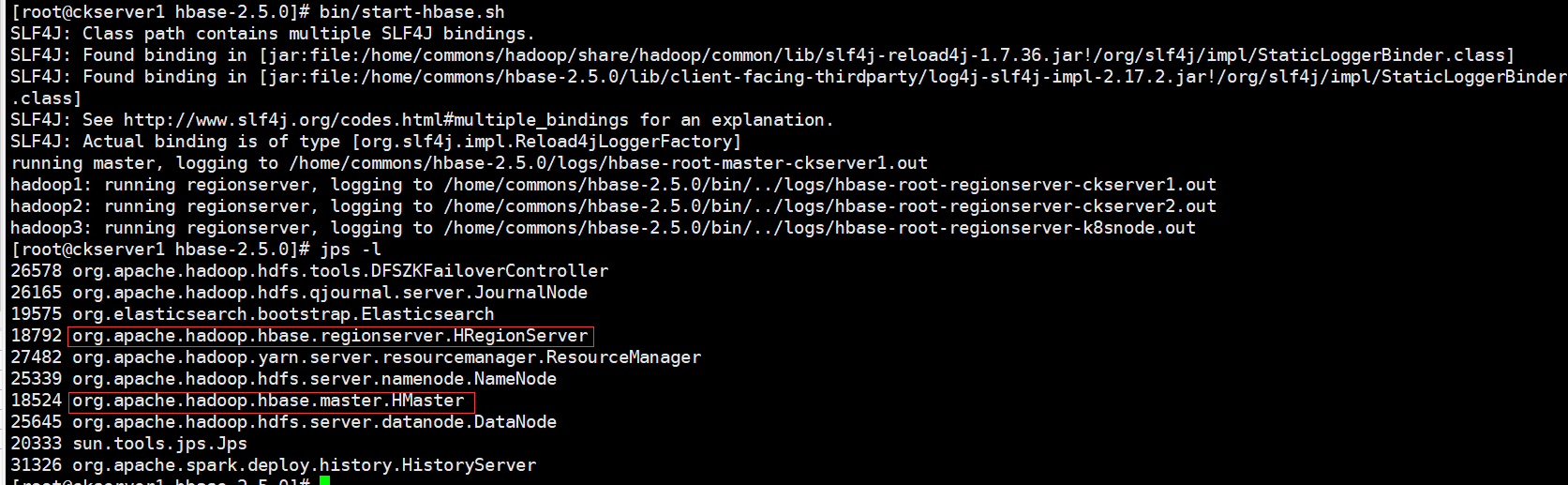
启动成功后,可以通过“host:port”的方式来访问 HBase 管理页面, http://hadoop1:16010
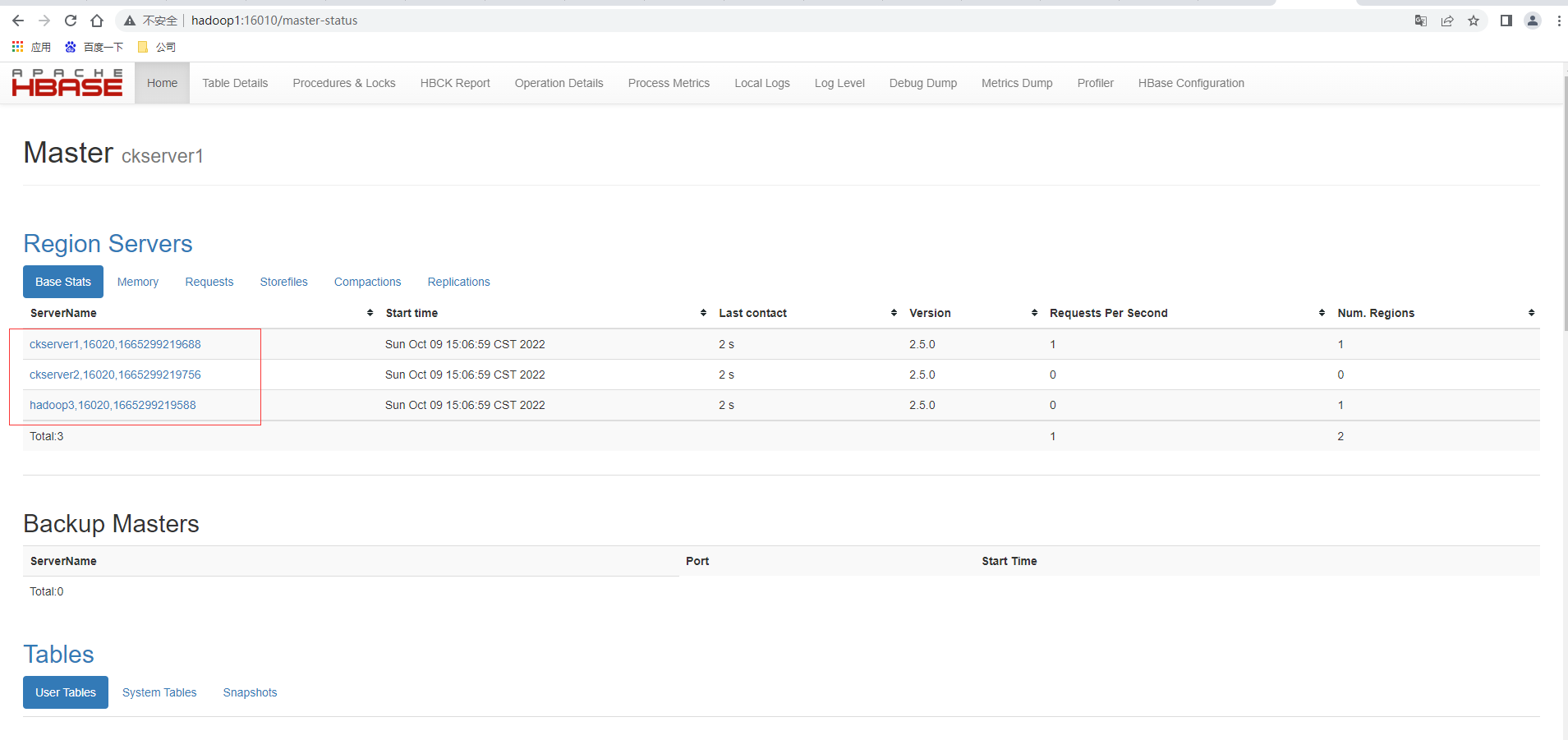
高可用
在 HBase 中 HMaster 负责监控 HRegionServer 的生命周期,均衡 RegionServer 的负载, 如果 HMaster 挂掉了,那么整个 HBase 集群将陷入不健康的状态,并且此时的工作状态并不 会维持太久。所以 HBase 支持对 HMaster 的高可用配置。
群启后查看服务进程,发现多了一个master进程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EteyEUXe-1665312413397)(image-20221009125044450.png)]
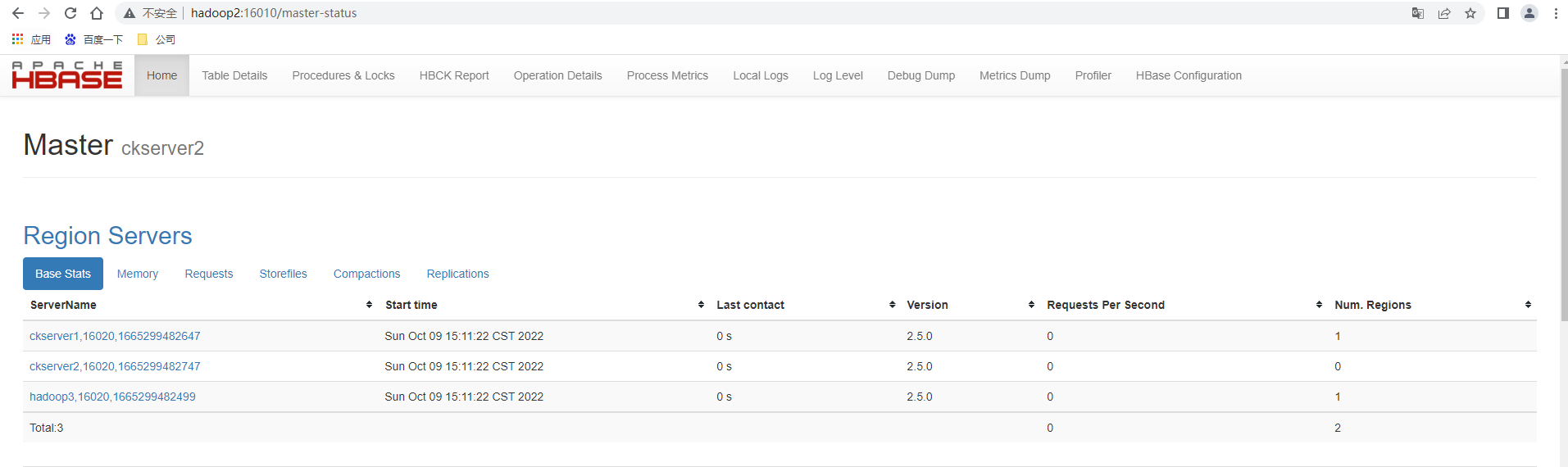
打开页面测试另一台master显示其为备用的Master,主master还是ckserver1也即是hadoop1,查看http://hadoop2:16010
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IePncDF4-1665312413398)(image-20221009125144397.png)]
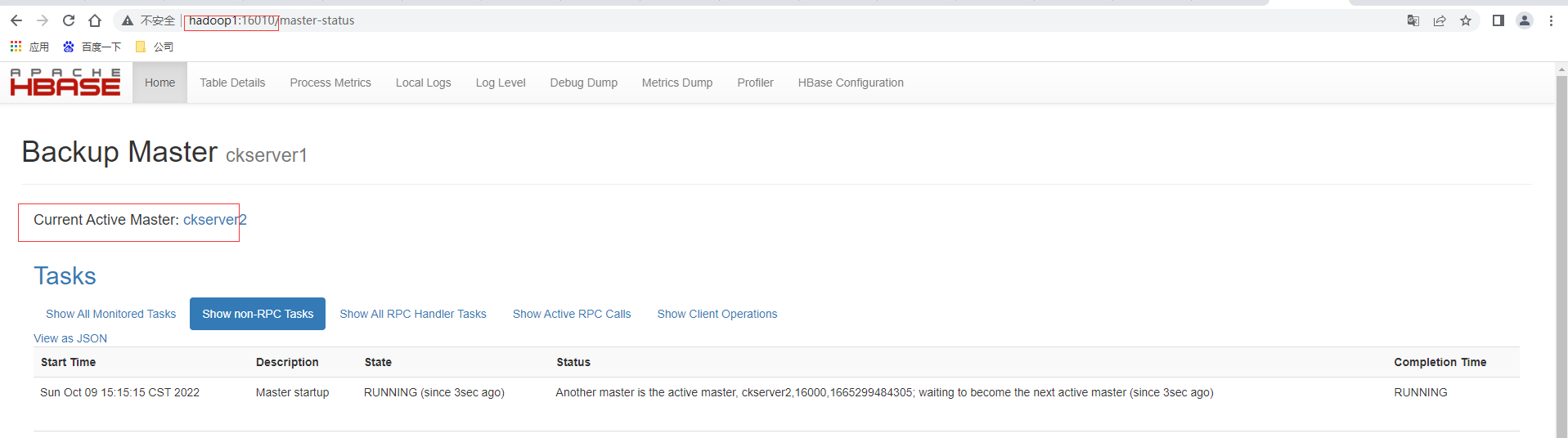
手动kill -9 杀死ckserver1也即是hadoop1上的HMaster进程,再次查看http://hadoop2:16010,发现主master已经成功的切换为ckserver2也即是hadoop2
然后再单独启动ckserver1也即是hadoop1上的HMaster,执行bin/hbase-daemon.sh start master,这时访问http://hadoop1:16010,发现hadoop1为备用master。
Shell操作
基础操作
命令空间
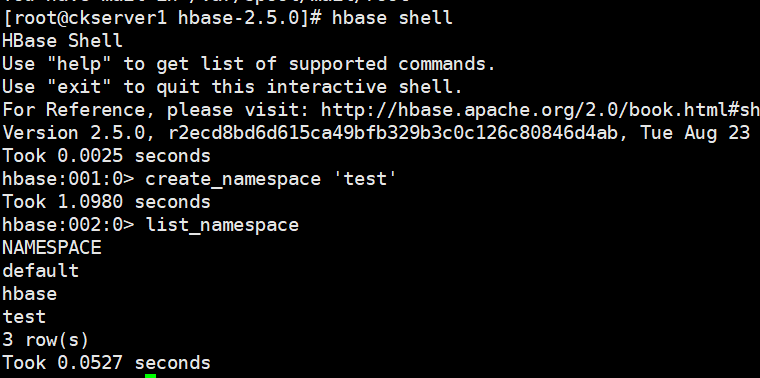
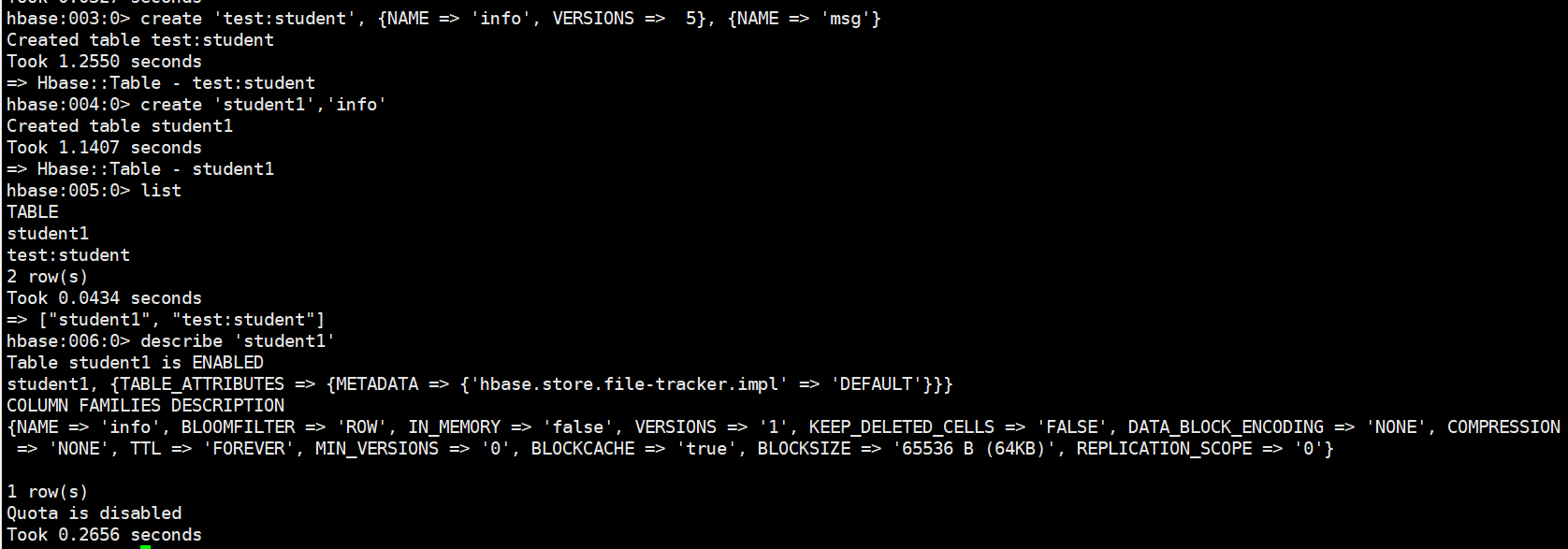
DDL
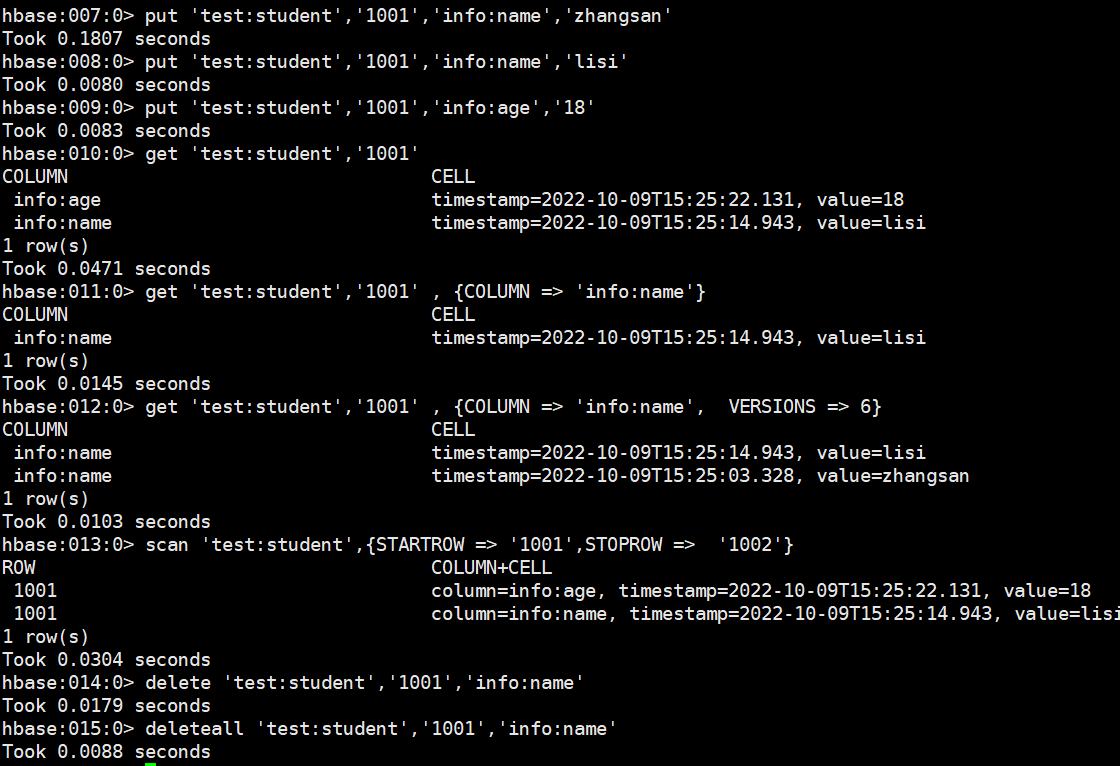
DML
标签: # HBase
留言评论