知识图谱实体对齐2:基于GNN嵌入的方法
1 导引
我们在上一篇博客《知识图谱实体对齐1:基于平移(translation)嵌入的方法》中介绍了如何对基于平移嵌入+对齐损失来完成知识图谱中的实体对齐。这些方法都是通过两个平移嵌入模型来将知识图谱\(\mathcal{G}_1\)和\(\mathcal{G}_2\)的重叠实体分别进行嵌入,并加上一个对齐损失来完成对齐。不过,除了基于平移的嵌入模型之外,是否还有其它方式呢?
答案是肯定的。目前已经提出了许多基于GNN的实体对齐方法[1],这些方法不仅采用GNN捕捉更多的实体结构化信息,还通过诸如参数共享、参数交换等方式在embedding模块中就使实体的embeddings尽可能统一到一个向量空间。
基于GNN的方法可以被分为基于GCN(graph convolutional network)的和基于GAT(graph attention network)两类,它们常常使用实体的邻居知识来对知识图谱的结构进行编码,大多数邻居及被做为嵌入模块的输入特征。因为这里存在一个假定,即对齐的实体将有相似的邻居。大多数基于GNN的方法在训练中只使用实体来做为对齐种子,而不是关系来做为对齐种子。
2 基于GNN的方法
2.1 GCN-Align
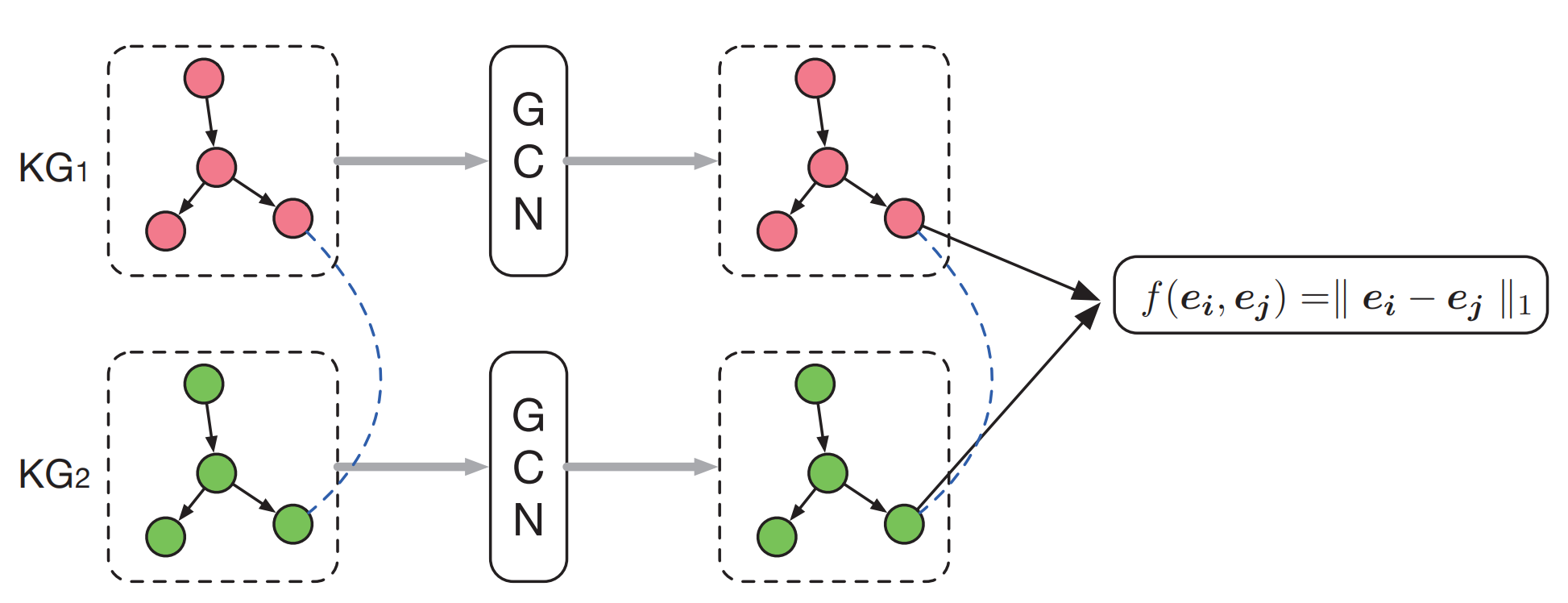
本文是第一篇采用GNN来进行实体对齐的工作[2]。GCN-Align使用两个GCN来将\(\mathcal{G}_1\)和\(\mathcal{G}_2\)的实体嵌入到一个统一的向量空间中(这两个GCN使用共享权重矩阵)。
(注:原论文除了实体embeddings,还还有个属性embedings,我们这里从简省略) 这里\(\boldsymbol{H}^{(l+1)}\)是实体的embeddings,\(\boldsymbol{W}^{(l)}\)是其对应的权重,\(\hat{\boldsymbol{A}}=\boldsymbol{A}+\boldsymbol{I}\)意为带自环的权重矩阵,\(\hat{\boldsymbol{D}}\)意为\(\hat{\boldsymbol{A}}\)的节点度矩阵(用于归一化使用)。
不过GCN-Align和GCN有所不同,GCN-Align在计算\(a\in \mathbb{A}\)时还考虑了不同的关系谓词。新的邻接矩阵计算如下:
这里函数\(g_h(r)\)和\(g_t(r)\)计算了由关系\(r\)连接的头实体和尾实体的数目再除以含有关系\(r\)的实体数量。\(\mathcal{T}\)为知识图谱中所有元组的集合。\((e_j, r, e_i)\)和\((e_i, r, e_j)\)都是KG中的元组。函数\(g_h(r)\)和\(g_t(r)\)分别计算关系\(r\)所连接的头实体和尾实体数量。这样,邻接矩阵\(\boldsymbol{A}\)就有助于对embedding信息如何在实体间传递进行建模。
然后,GCN-Align的训练也是由最小化间隔损失(参见我们上一篇博客《知识图谱实体对齐1:基于平移(translation)的方法》)来完成,其alignment score function定义为:
这里\(h(\cdot)\)表示维度为\(d\)的实体嵌入。
整个网络的架构如下:
2.2 HGCN
HGCN[3]在实体嵌入的过程中隐式地利用关系的表示来改善对齐过程。为了包含关系信息,HGCN同时学习实体和关系谓词的embeddings,
其整个包含embedding和align模块的框架如下:
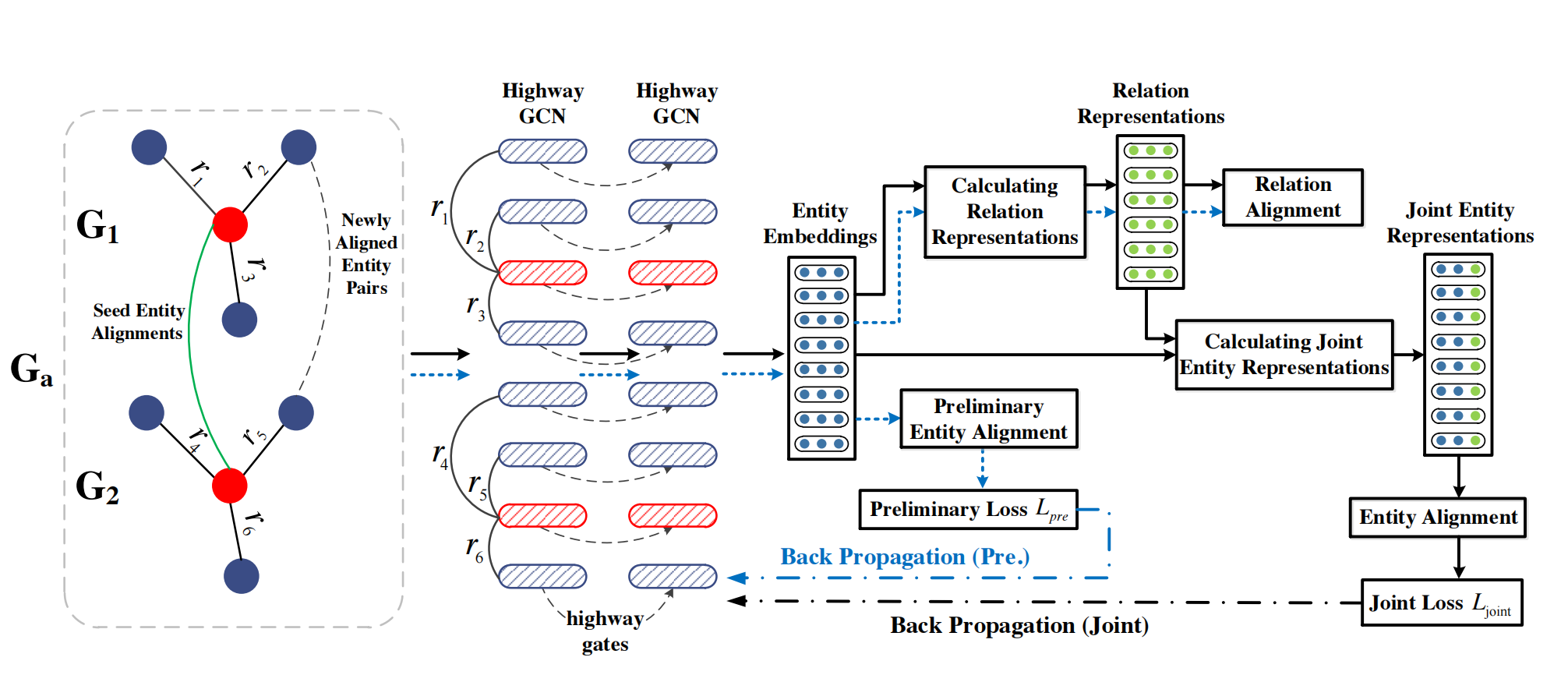
本文提出的框架可分为以下的三个阶段:
Stage 1
使用GCN的变种Highway-GCN来将实体嵌入到统一的向量空间。这里直接将\(\mathcal{G}_1\)和\(\mathcal{G}_2\)视作一个图\(G_a\),然后使用一个统一的GCN来获得\(G_a\)的实体嵌入:
我们这里采用逐层的highway gates(高速门)来建立Highway-GCN(HGCN)模型。逐层的highway gates用于控制GCN网络中的前向传播,写为以下的函数\(T\)的形式:
这里\(\boldsymbol{H}^{(l)}\)是\(l^{th}\)层的输出,\((l+1)^{th}\)层的输入。\(\odot\)是逐元素乘。
这样,HGCN分别计算两个KG的embeddings,并在训练中仍然使用上面所提到过的的alignment score function \(f_{\text{align}}(e_1, e_2)\)+间隔损失函数。
Stage 2
基于关系谓词的头实体和尾实体的表征来获得其embeddings。该阶段先分别计算所有连接关系谓词的头实体和尾实体的平均embeddings,接着这两个均值embeddings会在一个线性变换之后拼接起来做为关系的embeddings,这样就可以对跨知识图谱的关系进行对齐。
Stage 3
再次使用Highway-GCN(其输入为Stage 1中得到的embeddings和与该实体有关的关系谓词embeddings之和的拼接)做为共同的实体embeddings,然后alignment模块再次使用alignment score function + 间隔损失将两个知识图谱在Highway-GCN的输出映射到统一的向量空间。
2.3 GMNN
GMNN[4]将实体对齐问题形式化了为两个图之间做匹配的问题。传统的图匹配问题会通过对单语言知识图谱的事实进行编码,将每个知识图谱的实体投影到低维子空间。然而,对于跨语言问题,一些实体在不同的语言中可能存在不同的知识图谱事实,这可能导致其在在跨语言的实体embeddings中编码的信息具有差异性,从而使得这类方法难以对实体进行匹配。

如上图展示了我们对\(e_0\)和\(e_0'\)进行对齐的实例。但是在它们周围的邻居中只有一个对齐的邻居。这种方法得匹配只有很少的邻居的实体非常困难,因为缺乏足够的结构化信息。
为了解决这个缺点,作者提出了topic entity graph(主题实体图)来表征知识图谱中实体的上下文信息。不同于之前的方法使用实体embeddings来匹配实体,作者将这个任务建模为在topic entity graph之间进行图匹配。每个实体都对应一个topic entity graph(由相隔一跳的邻居和对应的关系谓词组成),这样的一个图能够表征实体的局部上下文信息。
该论文提出的由四层组成,包括输入表示层、node-level匹配层,graph-level匹配层和预测层。如下图所示:
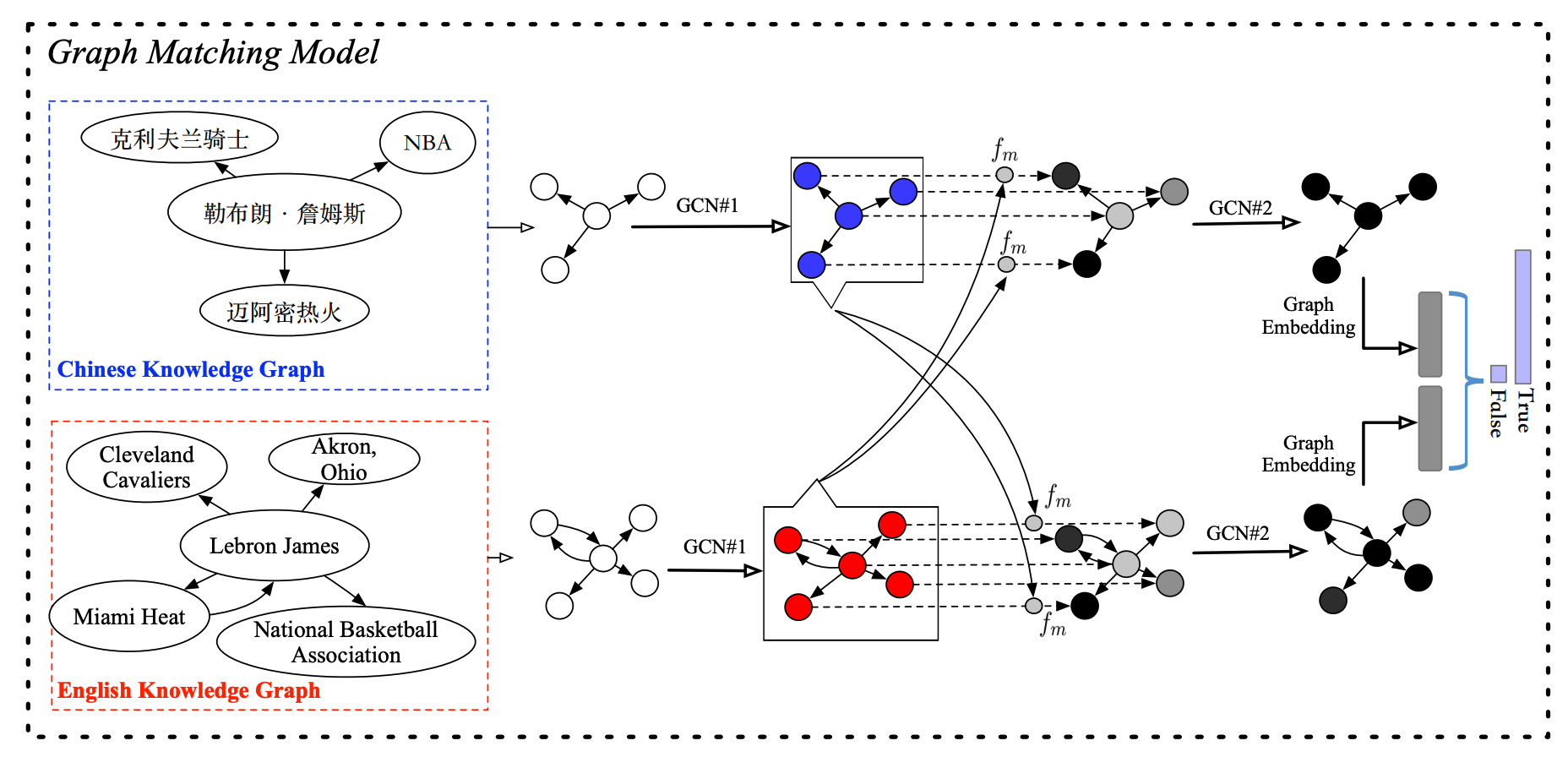
输入表示层使用GCN将两个topic graph进行编码并获得实体的embeddings。
node-level匹配层计算来自两个topic graph的实体对之间的余弦相似度。之后,这一层会计算实体embeddings的注意力加权和(attentive sum):
这里\(\alpha_{i,j}\)是某个topic graph中的实体\(i\)和另一个topic graph中的实体\(j\)之间的余弦相似度。接着,我们使用multi-perspective sine matching function\(f_m\)来计算\(\mathcal{G}_1\)和\(\mathcal{G}_2\)所有实体的匹配向量,如下式所示:
这里\(\bm{m} =f_m(\bm{v}_1, \bm{v}_2; \bm{W})\),其中\(\bm{m}_k \in \bm{m}\)是来自\(k\)个perspective的matching value,它根据两个向量线性变换后的余弦相似度进行计算:
之后,这个计算好的匹配向量会做为graph-level匹配层GCN的输入。graph-level匹配层的GCN会进一步传播局部的信息,而其输出embeddings会经过逐元素最大和平均池化方法被送入一个全连接神经网络来获得图的匹配表征。最后预测层将图的匹配表征作为softmax回归函数的输入来预测对齐实体。
2.4 MuGNN
MuGNN[5]强调用于对齐的不同知识图谱之间的结构异质性,因为这种结构异质性会导致需要对齐实体embeddings之间的不相似性。为了调和\(\mathcal{G}_1\)和\(\mathcal{G}_2\)之间的结构异质性,MuGNN在嵌入模块中使用多通道GNN以编码多通道图。形式化地,多通道GNN如下图所示,假定这里为双通道MuGNN:
这里\(\boldsymbol{A}_1\)由self-attention决定,\(a_{ij}\)是从\(e_i\)到\(e_j\)的连接权值,如下所示:
$ N_{e_i} \(是\)e_i\(的邻居,\)c_{ij}$是attention系数。
而\(\bm{A}_2\)通过降低互斥(exclusive)实体之间的连接权值来对互斥实体进行修剪。
这里\(\mathcal{R}_1\)和\(\mathcal{R}_2\)分别是\(\mathcal{G}_1\)和\(\mathcal{G}_2\)关系谓词的集合。当\(\left(e_i, r_1, e_j\right) \in \mathcal{T}_1\)时函数\(\mathbf{1}(\cdot)=1\),否则为0。函数\(\operatorname{sim}\left(r_1, r_2\right)\)为关系谓词\(r_1\)和\(r_2\)之间的内积相似度。
之后MuGNN的alignment模块采用了普通alignment score function的变种将来自多通道GNN的\(\mathcal{G}_1\)和\(\mathcal{G}_2\)的embeddings统一到相同的向量空间,该变种采用了种子实体对齐损失和种子关系谓词对齐损失的加权和。
改论文的框架整体架构如下:

2.5 NMN
NMN[6]也旨在解决不同知识图谱间的结构异质性。为了解决这个问题,该论文采用的方法同时学习了知识图谱的结构信息和邻居的差异,这样不同实体间的相似性就能够在结构异质性的情况下被捕捉。
为了学习知识图谱的结构信息,NMN的嵌入模块使用我们前面提到过的带有highway gates的GCN来对知识图谱的结构信息进行建模,其中将待对齐的\(\mathcal{G}_1\)和\(\mathcal{G}_2\)做为输入。这个模型使用种子对齐实体+基于间隔的损失函数进行预训练。之后,再使用跨图匹配来捕捉邻居的差异。之后,NMN将实体embeddings和邻居表示进行拼接以获得最终用于对齐的embeddings,其对齐操作是通过度量两个实体embeddings之间的欧几里得距离来完成。
该论文所提出方法的框架示意图如下所示:

2.6 CEA
CEA[7]考虑实体之间对齐决策的依赖性。比如一个实体如果已经被对齐到某个实体,那么它就不太可能再被做为对齐目标使用。该网络使用结构化、语义和字符串信号来捕捉源知识图谱和目标知识图谱实体之间在不同方面的相似度,而这由三个不同的相似度矩阵来表征。特别地,这里的结构化相似度矩阵会经由GCN并使用使用余弦相似度来计算,语义相似度矩阵由单词的embeddings来计算,字符串相似度矩阵由实体名称之间的Levenshtein距离计算。这三个矩阵之后会融合为一个矩阵。CEA之后会将实体嵌入形式化为一个在融合矩阵上的经典稳定匹配问题来捕捉相互依赖的EA决策。
3 参考文献
[1] Zhang R, Trisedya B D, Li M, et al. A benchmark and comprehensive survey on knowledge graph entity alignment via representation learning[J]. The VLDB Journal, 2022: 1-26
[2] Wang Z, Lv Q, Lan X, et al. Cross-lingual knowledge graph alignment via graph convolutional networks[C]//Proceedings of the 2018 conference on empirical methods in natural language processing. 2018: 349-357.
[3] Wu Y, Liu X, Feng Y, Wang Z, Zhao D (2019b) Jointly learning entity and relation representations for entity alignment. In: EMNLP 2019
[4] Cross-lingual knowledge graph alignment via graph matching neural network. In: ACL 2019
[5] Cao Y, Liu Z, Li C, Liu Z, Li J, Chua TS (2019) Multi-channel graph neural network for entity alignment. In: ACL 2019
[6] Wu Y, Liu X, Feng Y, Wang Z, Zhao D (2020) Neigh-borhood matching network for entity alignment. In: ACL 2020
[7] Zeng W, Zhao X, Tang J, Lin X (2020) Collective entity alignment via adaptive features. In: ICDE 2020
标签:
留言评论