本文是《vivo营销自动化技术解密》的第5篇文章,重点分析介绍在营销自动化业务中实时营销场景的背景价值、实时营销引擎架构以及项目开发过程中如何利用动态队列做好业务流量隔离,动态发布,使用规则引擎来提升营销规则的配置效率等几种关键技术设计实践。
《vivo营销自动化技术解密》系列文章:
一、背景
营销自动化的触达场景按照时效性划分主要有两大类:
1. 离线目标用户群发。
通过对业务离线数据的分析决策,制定合适的运营策略对目标用户进行群发触达。典型的场景有:新品推荐、活动预热、定期关怀、用户召回等。
2.实时个性化触达。
通过分析单个用户在一段指定时间内的行为轨迹,进行个性化的实时性营销触达。典型的场景有:支付提醒,满足活动条件触达等。
离线目标用户群发一般根据活动规则,T+n或者周期性对大数据离线用户数据进行批处理分析查询,获取满足条件的目标用户,从而进行营销触达。
需要关注的问题是:海量大数据的储存、查询性能和稳定性。而相比于离线目标用户群发,实时个性化触达对时效性的要求更高,一般来说触达效果也会更优,比如:
对24小时内收藏订单后,同时加入购物车的用户,push推送活动领券提醒;
对领取优惠券1小时内未使用的用户,推送使用提醒;
对活动期间成功下单总金额达到999元的用户,推送领取奖励提醒;
实时个性化触达需要关注问题包括:
1. 事件实时接入的高扩展性 。
需要快速支撑接入不同业务系统的各类行为事件和规则,需要进行统一的分发处理。
2.高性能高可靠统一分发处理。
3.复杂多源数据的处理。
包括数据的补全,各种规则指标的统计,目标用户的交并差计算。
4.高效可扩展的规则匹配。
对业务定义的各种复杂规则,需要有一套强扩展性的规则匹配工具。
二、核心架构设计分析
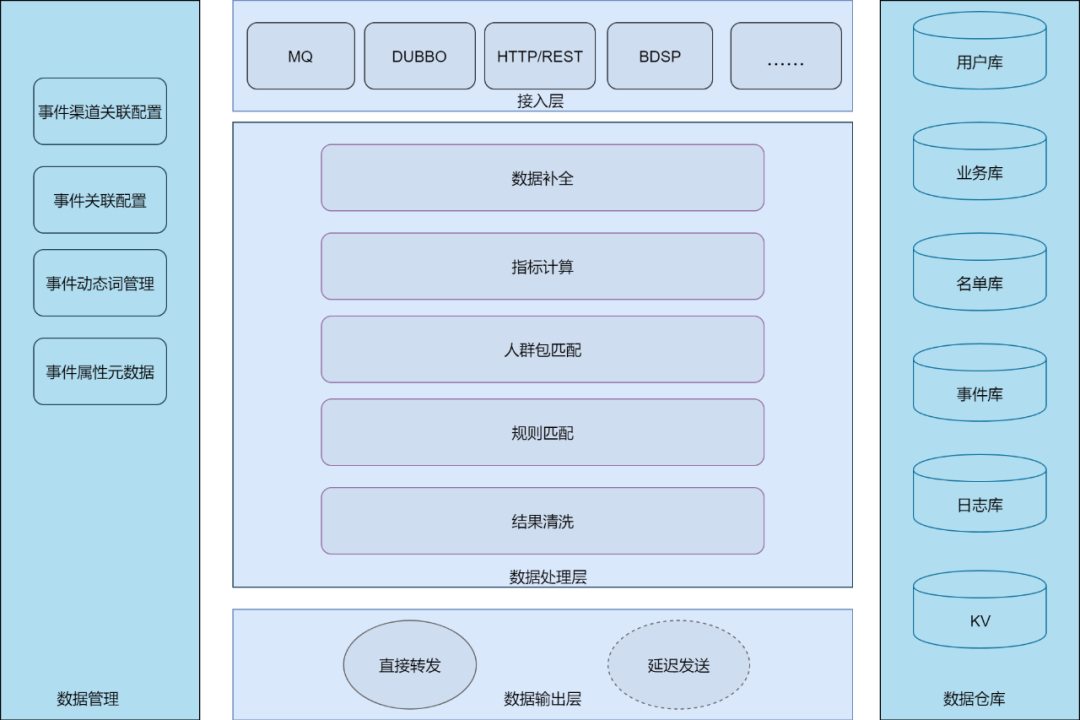
接入层
提供多种业务事件数据接入方式(比如支持异构外部系统的通用HTTP,内部的DUBBO、MQ等),最后转成MQ的方式统一分发。
由于事件数据源的不同,需要对宿主业务进行队列流量隔离管控,同时还需要评估后续队列的容量伸缩效率。
需要满足新增事件时,无需对系统进行重新部署,需要进行动态消息队列接入(下文会进行详细解析)。
数据处理层
实时引擎的核心部分。主要负责对事件数据进行加工处理,主要包括:
业务数据的统一标识补全,将多源数据进行打通关联。
对业务数据进行各种指标计算。常见的是基于时间窗口和会话窗口的流式计算,一般使用Flink来搭建。
目标用户匹配。常用的用户直接交并差集计算,能够更好的对目标用户进行实验。
业务规则匹配。基于业务逻辑对用户的数据进行匹配。
数据输出层
负责结果数据输出分发,主要目的是数据调配和触达发送策略。
数据管理
保存事件元数据的配置。
数据仓库
离线数据的储存,作用于流程中各种数据处理流程。
三、关键组件和流程设计
3.1 事件实时接入的扩展性设计
由于公司内部业务技术栈不尽相同,需要支持多种业务事件数据接入方式,比如通用HTTP接口,Java技术栈的DUBBO接口、和MQ消息队列的方式,为了系统内部可以进行统一管理,最后转成MQ的方式进行统一分发。
3.1.1 接入队列设计
由于事件数据源的不同,需要对宿主业务进行MQ队列流量管控隔离。不同业务系统事件接入需求有以下不同的设计方案:
方案一:为每个接入的事件创建一条新队列,不同事件使用不同队列。
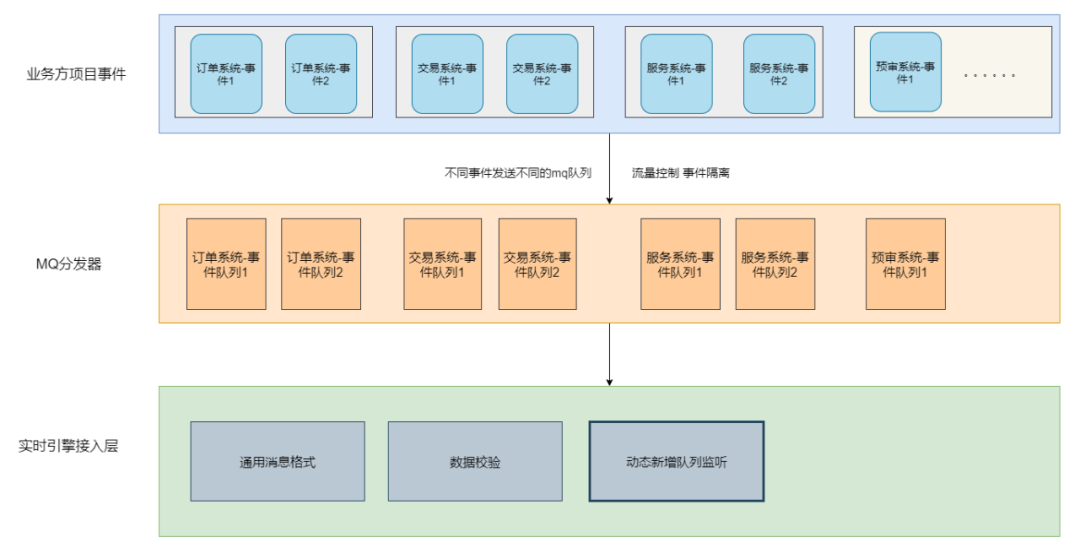
优点:最小粒度的流量控制,不同事件接入之间可以做到隔离,互不影响。
缺点:每次接入新事件都需要申请创建队列,随着事件接入数据增加,队列维护成本比较高。
方案二:同一接入方的事件使用同一队列,不同接入方使用不同队列(目前消息中心的方案)
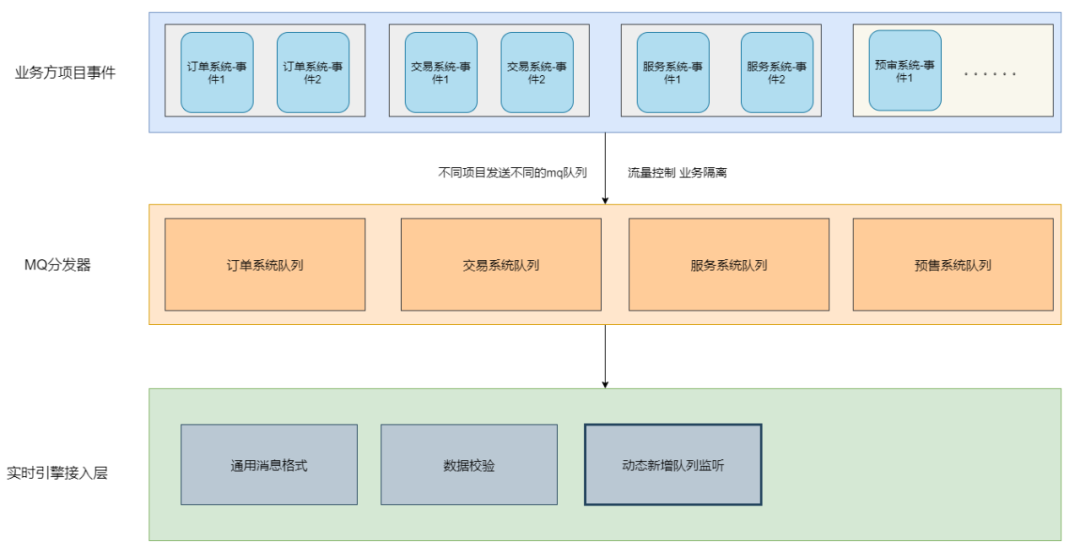
优点:按接入方来进行流量控制,接入方之间进行隔离,同一接入方只需在首次接入使用时创建队列,后续接入新事件无需创建。
缺点: 不同接入方接入时需要创建队列,同一接入方不隔离,有相互影响的风险。
方案三:不同接入方、事件均使用同一队列
优点:业务方使用友好,后续接入无需变更,耦合度小,方便切换MQ中间件。
缺点:最大粒度的流量控制,无法做到隔离,风险较高,需要经常进行队列扩容。
方案四:事先评估每个事件的优先级(如流量),高优先级的事件单独创建一条队列,低优先级的事件共用同一队列
优点:按事件的维度进行流量控制。
缺点:对接入方使用不够友好,不同业务接入时需要创建队列。
各方案对比如下:
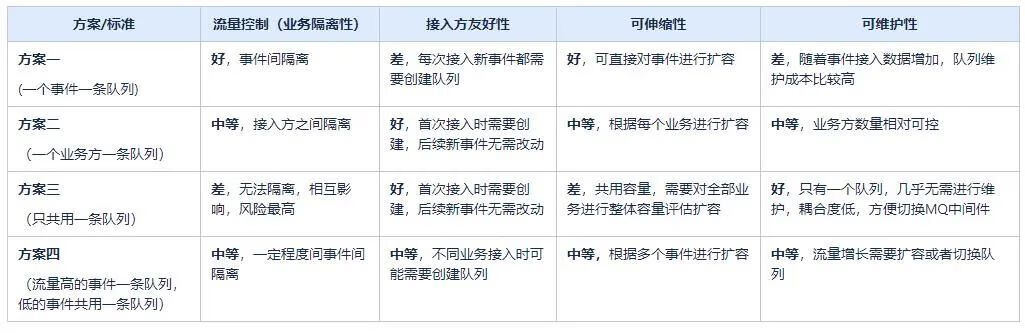
结论:按照当前项目优先级综合评估来看,业务隔离性>可伸缩性>可维护性>接入方友好性。
方案二比较适合 。(不同的项目可以根据自己的实际情况按优先级进行合适的选型)
3.1.2 动态消息监听
背景:当需要做好业务间风险隔离时,就必须按业务或者事件的维度进行队列拆分。此时若进行新接入事件就可能需要重新创建新的队列。
初期方案:采用公司中间件vivo-rmq, 当接入方需要新增队列时,需要修改代码新增队列监听,重新发版,这样做的问题是重新发版成本较高,按照项目流程管理进行效率低。
优化方案一: 修改启动加载类加载指定目录下的配置文件,新增队列时修改配置文件上传。
优点:无需发版。
缺点:仍需要重启服务器,同时需要维护配置文件目录等信息。
优化方案二:保存队列配置信息到数据表中,启用定时任务在服务器运行时动态监听数据库配置,新增或者下线队列配置记录后,自动进行队列变更。
优点:无需发版和重启。
缺点:定时任务实时性稍差,必须确保队列监听成功后在通知业务方接入。
结论:采用方案二,新增事件无需对系统进行重新部署,使用运行时动态方式进行消息队列接入。
3.2 统一分发处理
抽象公共分发模板:事件参数和有效性检测 → 分发到事件规则匹配器 EventMatcher → 输出到渠道发送流程
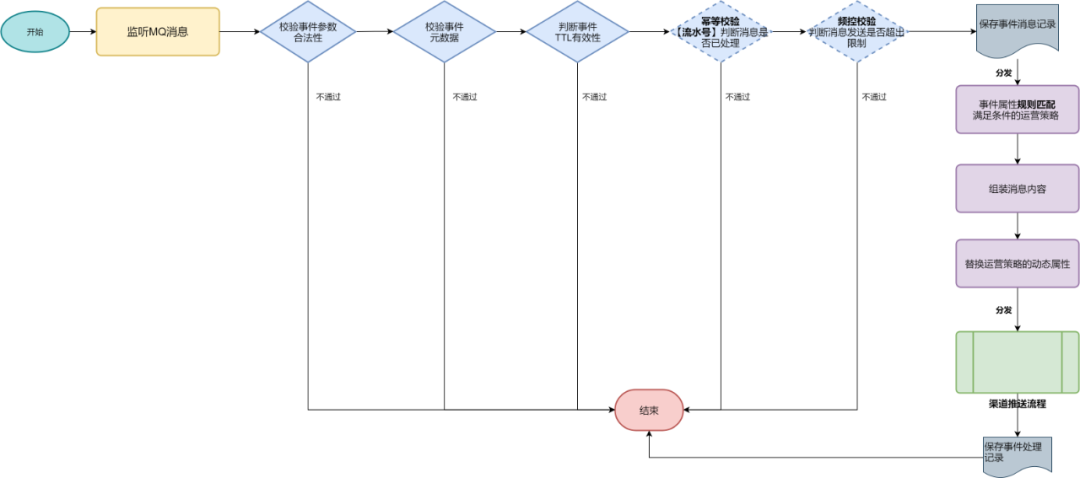
可靠平滑启停
1. MQ消费端分发主流程未处理完成,系统重启可能会造成事件消息丢失。
解决方案 :配置MQ消费端没有返回ack时,MQ服务端重新发送消息,此时业务消费必须保证幂等性。
2. MQ分发主流程处理完成已返回ack,但是在分发到业务线程池过程中 ,由于JVM重启而丢失。
解决方案 :这种场景时间极短,可以等待分发完成再进行ack。
3. MQ分发主流程分发到业务线程池处理过后, 但是线程池处理渠道发送过程仍可能因为JVM重启而丢失。
解决方案 :
利用JVM ShutdownHook钩子函数设置重启标记flag,MQ取数据时可以根据flag不再取出数据;
业务线程池不再接受新的任务, 同时利用线程池自身的Hook,等待处理线程池完成已有的任务。
3.3 复杂多源数据的处理
指标补全
业务接入方可以提前将业务数据加载到统一大数据平台,并补充元数据配置,支持实时事件数据之外的数据补全。
指标统计
对规则配置数据进行,使用Flink CEP负责事件处理,支持时间窗口计算。
交并差运算
基于Presto计算查询引擎,对不同目标用户群进行交并差负责运算,得到处理后的结果数据。
3.4 规则匹配器义
传统方案
使用简单直接的硬编码的方式,根据不同的事件条件进行编码处理,适合迭代更新要求低的小型系统。
传统方案存在的问题
硬编码开发成本高,交付时间长,难以应对需求变化。
业务规则重复累赘,难以维护。
业务规则发生变化需要修改代码,重启服务后才能生效。
规则引擎
狭义上的规则引擎是业务规则管理系统,英文名为BRMS(即Business Rule Management System),指一整套的规则管理解决方案。
而广义上的规则引擎是指一个可以将业务决策从应用程序代码中分离出来的输入输出组件,接收业务数据输入,并根据业务规则输出决策。
规则引擎重点关注的是:规则配置的通用性和扩展性,以及规则匹配的性能。
规则引擎优点
业务规则与系统代码分离,实现业务规则的集中管理。
在不重启服务的情况下可随时对业务规则进行扩展和维护。
可以动态修改业务规则,从而快速响应需求变更。
规则引擎是相对独立的,只关心业务规则,使得业务分析人员也可以参与编辑、维护系统的业务规则。
减少了硬编码业务规则的成本和风险。
使用规则引擎提供的规则编辑工具,使复杂的业务规则实现变得的简单。
规则引擎的实现选型
目前开源规则引擎 Drools、Easy Rules、表达式引擎Aviator,还有动态语言Groovy、甚至直接使用SpEL进行封装都可以作为规则引擎的一种实现方案。
如果需要搭建一整套完整BRMS的功能,从规则配置工作台,图形化语言建模,规则库管理等一站式解决方案,可以直接选用Drools。这也是大家认为Drools使用起来比较“重”的原因,组件繁多逻辑复杂,学习成本高。
如果业务场景相对简单,只是希望解决规则迭代频繁的问题,提升配置管理的扩展性,可以选用Easy Rules或者利用表达式引擎Aviator为基础搭建。
规则引擎常用应用场景
风险控制系统:风险贷款、风险评估
反欺诈项目:银行贷款、征信验证
决策平台系统:财务计算
促销平台系统:满减、打折、加价购等营销场景
其他应用场景
四、总结
本文重点分析介绍在营销自动化业务中实时营销引擎的设计,实时营销是通过分析单个用户在一段指定时间内的行为轨迹,产生动态的运营决策,可以对用户进行即时性的触达。
实时营销引擎架构设计主要分为事件接入、数据处理、指标计算、数据输出、元数据配置和数仓管理等模块。在项目开发过程我们利用队列隔离做好业务流量隔离,队列动态配置支持事件高效接入发布,统一分发处理提升流程的抽象化,平滑发布保障数据的可靠性,规则引擎来提升营销规则的配置效率。
标签: # vivo
留言评论