tensorflow1.0和tensorflow2.0的区别主要是1.0用的静态图
一般情况1.0已经足够,但是如果要进行深度神经网络的训练,当然还是tensorflow2.*-gpu比较快啦。
其中tensorflow有CPU和GPU两个版本(2.0安装方法),
CPU安装比较简单:
pip install tensorflow-cpu
一、查看显卡
日常CPU足够,想用GPU版本,要有NVIDIA的显卡,查看显卡方式如下:
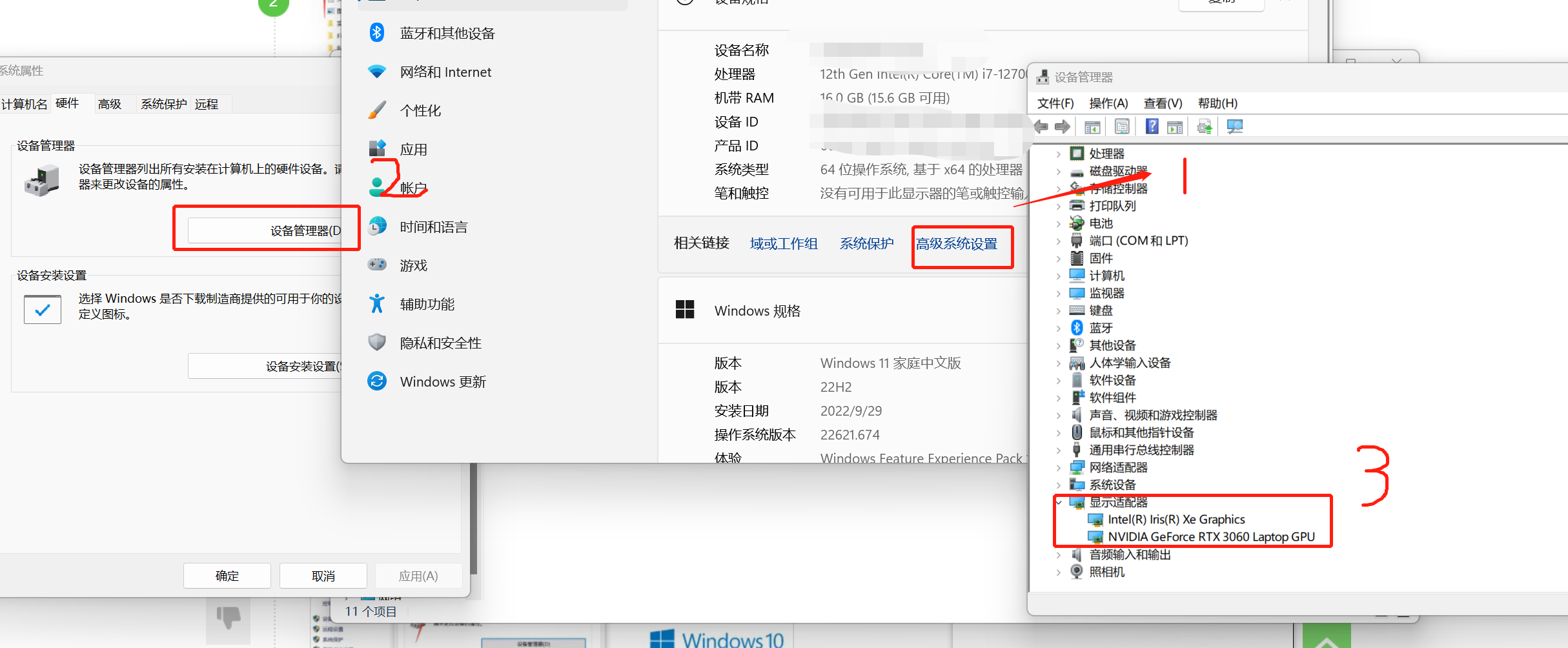
二、查看版本对应关系
然后我们需要去下载NVIDIA驱动CUDA以及支持神经网络训练的CUDNN模块:(重点,其中需要查看自己NVIDIA版本 Python版本 CUDNN版本是否匹配)
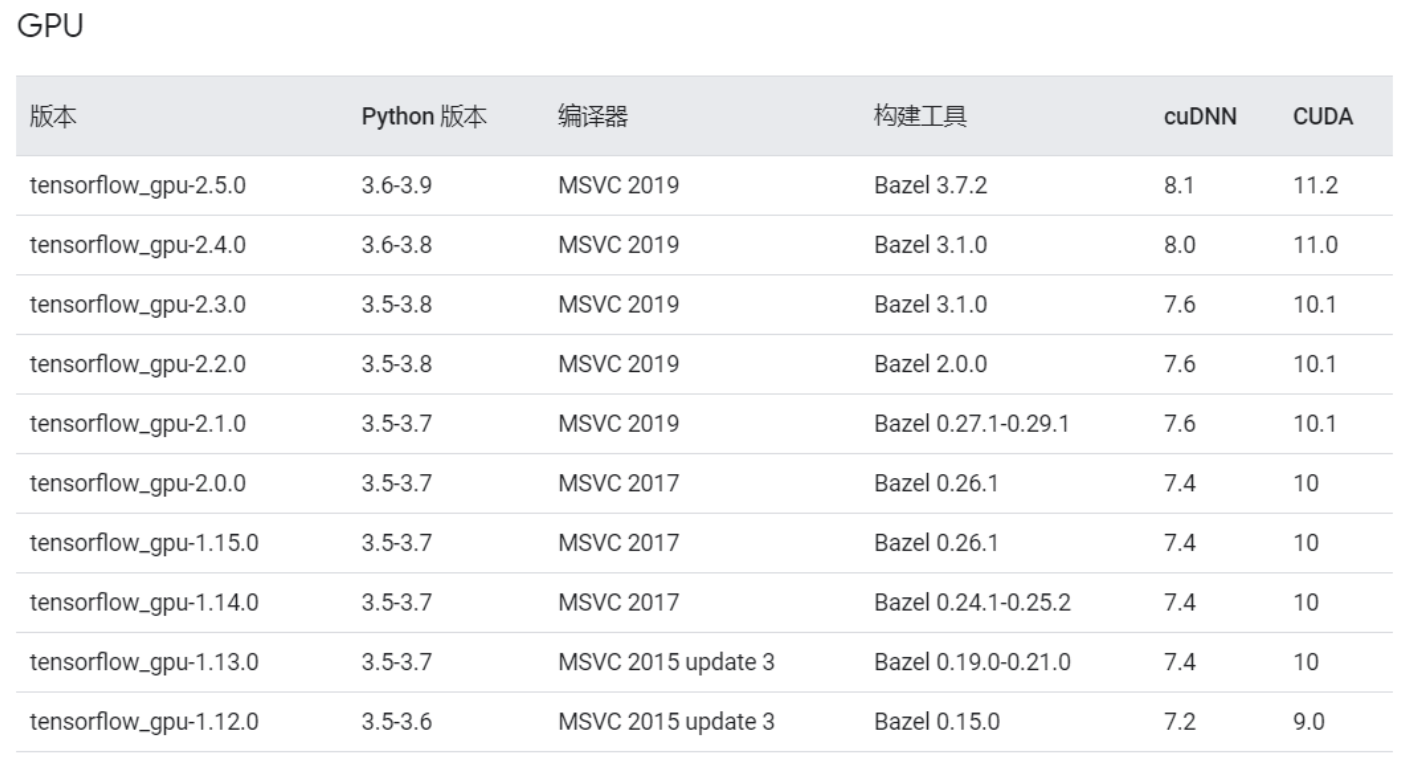
下载CUDA:https://developer.nvidia.com/cuda-11.3.0-download-archive
三、安装cudnn
CUDA安装完毕后,需要安装支持神经网络训练的CUDNN模块,下载 cuDNN,下载之前需要先注册一下 Nvidia 的账号,下载地址为:https://developer.nvidia.com/rdp/cudnn-download
下载完成之后将其解压,解压之后的目录如下:
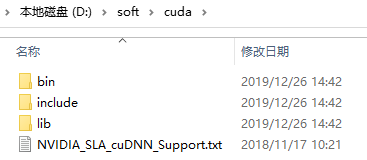
需要将以上三个文件复制到CUDA的安装目录中,通过上面的安装,我们将CUDA安装到了C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3中。
四、安装anaconda
安装Anaconda:
然后最好是使用anaconda安装tensorflow,先去安装anaconda,详细教程传送门:https://blog.csdn.net/fan18317517352/article/details/123035625
其实如果不想麻烦的配置环境变量,可以在安装Anaconda过程中选择JUST ME, 然后将Anaconda加入环境变量。
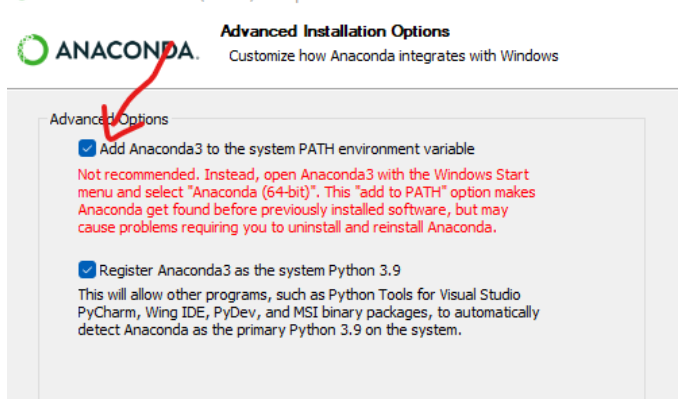
然后直接就可以在anaconda里选择tensorflow-gpu进行安装,安装完毕后,查看能否支持gpu:
import os
import tensorflow as tf
print(tf.test.is_gpu_available())
gpus = tf.config.list_physical_devices('GPU')
cpus = tf.config.list_physical_devices('CPU')
print(gpus, cpus)
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
如果输出如下,则说明可以使用GPU
(注意,真的只是可以使用,不代表可以用了,自己体会,我曾经被坑了好久):
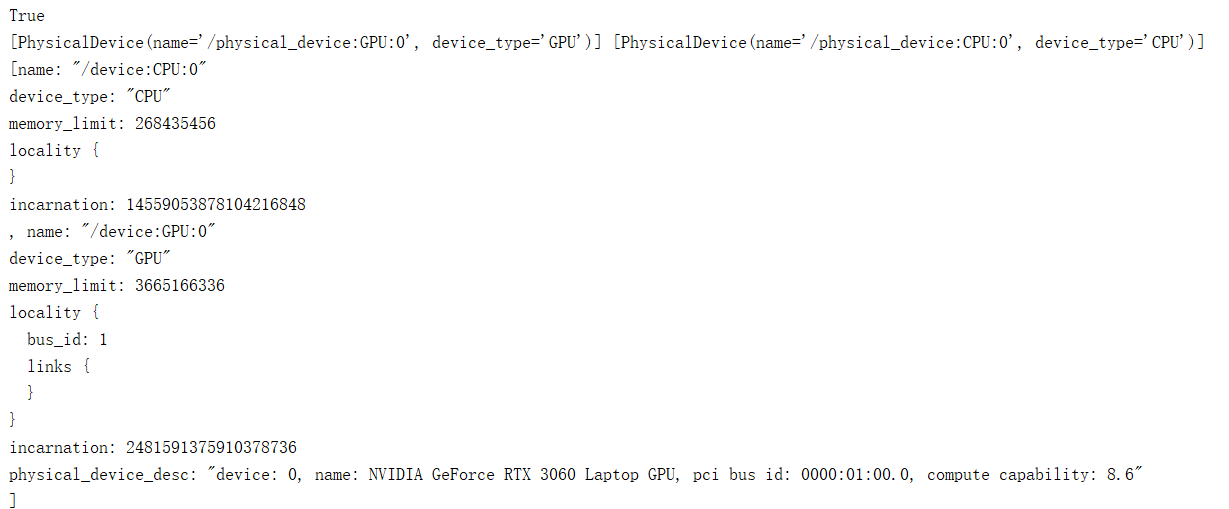
五、测试(重点干货来了)
import os # 指定使用0卡 os.environ["CUDA_VISIBLE_DEVICES"] = "0"
如果提示缺少dll文件,去这个网址找:https://cn.dll-files.com/cudart64_110.dll.html 缺啥找啥,看链接后缀
然后训练模型,发现只能训练前馈神经网络,速度还很慢,训练深度网络时,直接内存不足,但原因可能是由于缺少文件:
Process finished with exit code -1073740791 (0xC0000409)

解决办法:Pycharm中,点击RUN-EDIT CONFIGURATIONS,输出错误信息

发现缺少文件:

下载zlib并且解压
dll放到cuda安装目录的bin里,lib放到cuda安装目录的lib文件夹下,然后开始训练,你会发现用GPU真香
CPU耗时:

GPU耗时:

切换CPU GPU 只要切换设备就行了,我只进行了2epoch的卷积训练,可以看到GPU速度要比CPU快个4 5 倍左右,如果是前馈神经网络或者简单的神经网络,测试验证使用CPU是被GPU要快的,所以自己需要根据实际情况切换设备。
需要zlib文件的可以给我留言。
标签:
留言评论